Apache NiFi notes
Russell Bateman
January 2016
last update:
|
|
Apache NiFi notes
|
(See A simple NiFi processor project for minimal source code and pom.xml files.)
Managing templates in NiFi 1.x. Go here for the best illustrated guide demonstrating Apache NiFi templates or go here: NiFi templating notes.
(How to get NiFi to... work (unsecurely) as before for personal use.)
PrefaceThe notes are in chronological order, as I needed and made them. I haven't yet attempted to organize them more usefully. The start happens below under Friday, 15 January 2016. According to Wikipedia, NiFi originated at the NSA where it originally bore the name, Niagarafiles (from Niagara Falls). It was made open source, then picked up for continued development by Onyara, Inc., a start-up company later acquired by Hortonworks in August, 2015. NiFi has been described as a big-data technology, as "data in motion," in opposition to Hadoop, which is "data at rest." Apache NiFi is the perfect tool for performing extract, transfer and load (ETL) of data records. It is a somewhat low-code environment and IDE for developing data pipelines. The principal NiFi developer documentation is cosmetically beautiful, however, it suffers from being written very much by someone who already thoroughly understands his topic without the sensitivity that his audience do not. Therefore, it's a great place to go to as a reference, but rarely as a method. One can easily become acquainted with the elements of what must be done, but rarely if ever know how to write the code to access those elements let alone the best way to do it. For method documentation, a concept in language learning, which often only appears for technology such as NiFi long after the fact in our industry, you'll need to look fort the "how-to" stuff in the bulleted list below, as well as in my notes here. |
NiFi 1.x UI overview and other videos |
My goal in writing this page is a) to record what I've learned for later reference and b) to leave breadcrumbs for others like me.
In my company, we were doing extract, load and transfer (ETL) by way of a hugely complicated and proprietary monolith that was challenging to understand. I had proposed beginning to abandon it in favor of using a queue-messaging system, something I was very familiar with. A few months later, a director discovered NiFi and put my colleague up to looking into it. Earlier on, I glanced at it, but was swamped on a project and did not pursue it until after my colleague had basically adopted and promoted it as a replacement for our old ETL process. It only took us a few weeks to a) create a shim by which our existing ETL component code became fully exploitable and b) spin up a number of NiFi-native components including ports of some of the more important, legacy ones. For me, the road has been a gratifying one: I no longer need to grok the old monolith and can immediately contribute to the growing number of processors to do very interesting things. It leveled my own playing field as a newer member of staff.
Stuff I don't have to keep in the pile that's my brain because I just look here (rather than deep down inside these chronologically recorded notes):
@Test
public void test() throws Exception
{
TestRunner runner = TestRunners.newTestRunner( new ExcerptBase64FromHl7() );
final String HL7 =
"MSH|^~\\&|Direct Email|XYZ|||201609061628||ORU^R01^ORU_R01|1A160906202824456947||2.5\n"
+ "PID|||000772340934||TEST^Sandoval^||19330801|M|||1 Mockingbird Lane^^ANYWHERE^TN^90210^||\n"
+ "PV1||O\n"
+ "OBR||62281e18-b851-4218-9ed5-bbf392d52f84||AD^Advance Directive"
+ "OBX|1|ED|AD^Advance Directive^3.665892.1.238973.3.1234||^multipart^^Base64^"
+ "F_ABCDEFGHIJKLMNOPQRSTUVWXYZ";
// mock up some attributes...
Map< String, String > attributes = new HashMap<>();
attributes.put( "attribute-name", "attribute-value" );
attributes.put( "another-name", "another-value" );
// mock up some properties...
runner.setProperty( ExcerptBase64FromHl7.A_STATIC_PROPERTY, "static-property-value" );
runner.setProperty( "dynamic property", "some value" );
// add a dynamic property...
runner.setValidateExpressionUsage( false );
runner.setProperty( "property-name", "value" );
// call the processor...
runner.setValidateExpressionUsage( false );
runner.enqueue( new ByteArrayInputStream( HL7.getBytes() ), attributes );
runner.run( 1 );
runner.assertQueueEmpty();
// gather the results...
List< MockFlowFile > results = runner.getFlowFilesForRelationship( ExcerptBase64FromHl7.SUCCESS );
assertTrue( "1 match", results.size() == 1 );
MockFlowFile result = results.get( 0 );
String actual = new String( runner.getContentAsByteArray( result ) );
assertTrue( "Missing binary content", actual.contains( "1_ABCDEFGHIJKLMNOPQRSTUVWXYZ" ) );
// ensure the processor transmitted the attribute...
String attribute = result.getAttribute( "attribute-name" );
assertTrue( "Failed to transmit attribute", attribute.equals( "attribute-value" ) );
}
Here is a collection of some NiFi notes...
Update, February 2017: what's the real delta between 0.x and 1.x? Not too much until you get down into gritty detail, something you won't do when just acquainting yourself.
Now I'm looking at:
Unsuccessful last Friday, I took another approach to working on the NiFi example from IntelliJ IDEA. By no means do I think it must be done this way, however, Eclipse was handy for ensuring stuff got set up correctly. The article assumes much about setting up a project.
The pom.xml. There are several ultra-critical relationships to beware of.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>rocks.nifi</groupId>
<artifactId>examples</artifactId> <!-- change this to change project name -->
<version>1.0-SNAPSHOT</version>
<packaging>nar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<nifi.version>0.4.1</nifi.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-api</artifactId>
<version>${nifi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-utils</artifactId>
<version>${nifi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-processor-utils</artifactId>
<version>${nifi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-mock</artifactId>
<version>${nifi.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-nar-maven-plugin</artifactId>
<version>1.0.0-incubating</version>
<extensions>true</extensions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.15</version>
</plugin>
</plugins>
</build>
</project>
<!-- vim: set tabstop=2 shiftwidth=2 expandtab: -->
Of course, once you've also created JsonProcessor.java at the end of the package created, you just do as the article says. You should end up with:
~/dev/nifi/projects/json-processor $ tree . ├── pom.xml └── src ├── main │ ├── java │ │ └── rocks │ │ └── nifi │ │ └── examples │ │ └── processors │ │ └── JsonProcessor.java │ └── resources │ └── META-INF │ └── services │ └── org.apache.nifi.processor.Processor └── test └── java └── rocks └── nifi └── examples └── processors └── JsonProcessorTest.java 16 directories, 4 files
The essential is:
The IntelliJ IDEA project can be opened as usual in place of Eclipse. Here's success:
See NiFi Developer's Guide: Processor API for details on developing a processor, what I've just done. Importantly, this describes
Here's an example from NiFi Rocks:
package rocks.nifi.examples.processors;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.concurrent.atomic.AtomicReference;
import com.jayway.jsonpath.JsonPath;
import org.apache.commons.io.IOUtils;
import org.apache.nifi.annotation.behavior.SideEffectFree;
import org.apache.nifi.annotation.documentation.CapabilityDescription;
import org.apache.nifi.annotation.documentation.Tags;
import org.apache.nifi.components.PropertyDescriptor;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.logging.ProcessorLog;
import org.apache.nifi.processor.AbstractProcessor;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.ProcessorInitializationContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.exception.ProcessException;
import org.apache.nifi.processor.io.InputStreamCallback;
import org.apache.nifi.processor.io.OutputStreamCallback;
import org.apache.nifi.processor.util.StandardValidators;
/**
* Our NiFi JSON processor from
* http://www.nifi.rocks/developing-a-custom-apache-nifi-processor-json/
*/
@SideEffectFree
@Tags( { "JSON", "NIFI ROCKS" } ) // for finding processor in the GUI
@CapabilityDescription( "Fetch value from JSON path." ) // also displayed in the processor selection box
public class JsonProcessor extends AbstractProcessor
{
private List< PropertyDescriptor > properties; // one of these for each property of the processor
private Set< Relationship > relationships; // one of these for each possible arc away from the processor
@Override public List< PropertyDescriptor > getSupportedPropertyDescriptors() { return properties; }
@Override public Set< Relationship > getRelationships() { return relationships; }
// our lone property...
public static final PropertyDescriptor JSON_PATH = new PropertyDescriptor.Builder()
.name( "Json Path" )
.required( true )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.build();
// our lone relationship...
public static final Relationship SUCCESS = new Relationship.Builder()
.name( "SUCCESS" )
.description( "Succes relationship" )
.build();
/**
* Called at the start of Apache NiFi. NiFi is a highly multi-threaded environment; be
* careful what is done in this space. This is why both the list of properties and the
* set of relationships are set with unmodifiable collections.
* @param context supplies the processor with a) a ProcessorLog, b) a unique
* identifier and c) a ControllerServiceLookup to interact with
* configured ControllerServices.
*/
@Override
public void init( final ProcessorInitializationContext context )
{
List< PropertyDescriptor > properties = new ArrayList<>();
properties.add( JSON_PATH );
this.properties = Collections.unmodifiableList( properties );
Set< Relationship > relationships = new HashSet<>();
relationships.add( SUCCESS );
this.relationships = Collections.unmodifiableSet( relationships );
}
/**
* Called when ever a flowfile is passed to the processor. The AtomicReference
* is required because in order to have access to the variable in the call-back scope it
* needs to be final. If it were just a final String it could not change.
*/
@Override
public void onTrigger( ProcessContext context, ProcessSession session ) throws ProcessException
{
final ProcessorLog log = this.getLogger();
final AtomicReference< String > value = new AtomicReference<>();
FlowFile flowfile = session.get();
// ------------------------------------------------------------------------
session.read( flowfile, new InputStreamCallback()
{
/**
* Uses Apache Commons to read the input stream out to a string. Uses
* JsonPath to attempt to read the JSON and set a value to the pass on.
* It would normally be best practice in the case of a exception to pass
* the original flowfile to a Error relation point.
*/
@Override
public void process( InputStream in ) throws IOException
{
try
{
String json = IOUtils.toString( in );
String result = JsonPath.read( json, "$.hello" );
value.set( result );
}
catch( Exception e )
{
e.printStackTrace();
log.error( "Failed to read json string." );
}
}
} );
// ------------------------------------------------------------------------
String results = value.get();
if( results != null && !results.isEmpty() )
flowfile = session.putAttribute( flowfile, "match", results );
// ------------------------------------------------------------------------
flowfile = session.write( flowfile, new OutputStreamCallback()
{
/**
* For both reading and writing to the same flowfile. With both the
* outputstream call-back and stream call-back remember to assign it
* back to a flowfile. This processor is not in use in the code, but
* could have been. The example was deliberate to show a way of moving
* data out of callbacks and back in.
*/
@Override
public void process( OutputStream out ) throws IOException
{
out.write( value.get().getBytes() );
}
} );
// ------------------------------------------------------------------------
/* Every flowfile that is generated needs to be deleted or transfered.
*/
session.transfer( flowfile, SUCCESS );
}
/**
* Called every time a property is modified in case we want to do something
* like stop and start a Flowfile over in consequence.
* @param descriptor indicates which property was changed.
* @param oldValue value unvalidated.
* @param newValue value unvalidated.
*/
@Override
public void onPropertyModified( PropertyDescriptor descriptor, String oldValue, String newValue ) { }
}
(See this note for interacting with a flowfile in both input- and output modes at once.)
Before anything else, the processor's init() method is called. It looks like this happens at NiFi start-up rather than later when the processor is actually used.
The processor must expose to the NiFi framework all of the Relationships it supports. The relationships are the arcs in the illustration below.
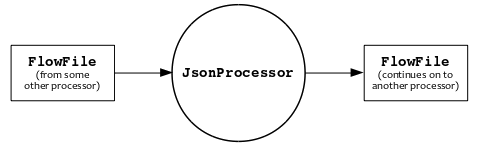
Performing the work. This happens when onTrigger() is called (by the framework).
The onTrigger() method is passed the context and the session, and it must:
A processor won't in fact be triggered, even if it has one or more FlowFile in its queue if the framework, checking downstream destinations (i.e. all other processors) and these are full. There is an annotation, @TriggerWhenAnyDestinationAvailable, which when present will allow the FlowFile to be processed as long as it can advance to the next processor.
@TriggerSerially will make the processor work as single-threaded. However, the processor implementation must still be thread-safe as the thread of execution may change.
Properties are exposed to the web interface via public method, but the properties themselves are locked using Collections.unmodifiableList() (if coded that way). If a property is changed as a processor is running, the latter can react eagerly if it implements onPropertyModified().
(There is no sample code of validating processor properties. Simply, the customValidate() method is called with a validation context and any that describe problems are returned . (But, is this implemented?)
protected Collection< ValidationResult > customValidate( ValidationContext validationContext )
{
return Collections.emptySet();
}
It's possible to augment initialization and enabling lifecycles through Java annotion. Some of these apply only to processor components, some to controller components, some to reporting tasks, to one or more.
There's a way to document various things that reach the user level like properties and relationships. This is done through annotation, see Documenting a Component and see the JSON processor sample code at the top of the class.
"Advanced documentation," what appears when a user right-clicks a processor in the web UI, provides a Usage menu item. What goes in there is done in additionalDetails.html. This file must be dropped into the root of the processor's JAR (NAR) file in subdirectory, docs. See Advanced Documentation.
In practice, this might be a little confusing. Here's an illustration. If I were going to endow my sample JSON processor with such a document, it would live here (see additionalDetails.html below):
~/dev/nifi/projects/json-processor $ tree . ├── pom.xml └── src ├── main │ ├── java │ │ └── rocks │ │ └── nifi │ │ └── examples │ │ └── processors │ │ └── JsonProcessor.java │ └── resources │ ├── META-INF │ │ └── services │ │ └── org.apache.nifi.processor.Processor │ └── docs │ └── rocks.nifi.examples.processors.JsonProcessor │ └── additionalDetails.html └── test └── java └── rocks └── nifi └── examples └── processors └── JsonProcessorTest.java 18 directories, 5 files
When one gets Usage from the context menu, an index.html is generated that "hosts" additionalDetails.html, but covers standard, default NiFi processor topics including auto-generated coverage of the current processor (based on what NiFi knows about properties and the like). additionalDetails.html is only necessary if that index.html documentation is inadequate.
Gathering resources (see dailies for today).
package com.etretatlogiciels.nifi.python.filter;
import org.apache.commons.io.IOUtils;
import org.apache.nifi.annotation.documentation.CapabilityDescription;
import org.apache.nifi.annotation.documentation.Tags;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.processor.AbstractProcessor;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.ProcessorInitializationContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.exception.ProcessException;
import org.apache.nifi.processor.io.OutputStreamCallback;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
@Tags( { "example", "resources" } )
@CapabilityDescription( "This example processor loads a resource from the nar and writes it to the FlowFile content" )
public class WriteResourceToStream extends AbstractProcessor
{
public static final Relationship REL_SUCCESS = new Relationship.Builder().name( "success" )
.description( "files that were successfully processed" )
.build();
public static final Relationship REL_FAILURE = new Relationship.Builder().name( "failure" )
.description( "files that were not successfully processed" )
.build();
private Set< Relationship > relationships;
private String resourceData;
@Override protected void init( final ProcessorInitializationContext context )
{
final Set< Relationship > relationships = new HashSet<>();
relationships.add( REL_SUCCESS );
relationships.add( REL_FAILURE );
this.relationships = Collections.unmodifiableSet( relationships );
final InputStream resourceStream = Thread.currentThread().getContextClassLoader().getResourceAsStream( "file.txt" );
try
{
this.resourceData = IOUtils.toString( resourceStream );
}
catch( IOException e )
{
throw new RuntimeException( "Unable to load resources", e );
}
finally
{
IOUtils.closeQuietly( resourceStream );
}
}
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
FlowFile flowFile = session.get();
if( flowFile == null )
return;
try
{
flowFile = session.write( flowFile, new OutputStreamCallback()
{
@Override public void process( OutputStream out ) throws IOException
{
IOUtils.write( resourceData, out );
}
} );
session.transfer( flowFile, REL_SUCCESS );
}
catch( ProcessException ex )
{
getLogger().error( "Unable to process", ex );
session.transfer( flowFile, REL_FAILURE );
}
}
}
I need to figure out how to get property values. The samples I've seen so far pretty well avoid that. So, I went looking for it this morning and found it looking in the implementation of GetFile, a processor that comes with NiFI. Let me fill in the context here and highlight the actual statement below:
@TriggerWhenEmpty
@Tags( { "local", "files", "filesystem", "ingest", "ingress", "get", "source", "input" } )
@CapabilityDescription( "Creates FlowFiles from files in a directory. "
+ "NiFi will ignore files it doesn't have at least read permissions for." )
public class GetFile extends AbstractProcessor
{
public static final PropertyDescriptor DIRECTORY = new PropertyDescriptor.Builder()
.name( "input directory" ) // internal name (and used if displayName missing)*
.displayName( "Input Directory" ) // public name seen in UI
.description( "The input directory from which to pull files" )
.required( true )
.addValidator( StandardValidators.createDirectoryExistsValidator( true, false ) )
.expressionLanguageSupported( true )
.build();
.
.
.
@Override
protected void init( final ProcessorInitializationContext context )
{
final List< PropertyDescriptor > properties = new ArrayList<>();
properties.add( DIRECTORY );
.
.
.
}
.
.
.
@OnScheduled
public void onScheduled( final ProcessContext context )
{
fileFilterRef.set( createFileFilter( context ) );
fileQueue.clear();
}
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
final File directory = new File( context.getProperty( DIRECTORY ).evaluateAttributeExpressions().getValue() );
final boolean keepingSourceFile = context.getProperty( KEEP_SOURCE_FILE ).asBoolean();
final ProcessorLog logger = getLogger();
.
.
.
}
}
* See Sets a unique id for the property. This field is optional and if not specified the PropertyDescriptor's name will be used as the identifying attribute. However, by supplying an id, the PropertyDescriptor's name can be changed without causing problems. This is beneficial because it allows a User Interface to represent the name differently.
Originally, NiFi just had one of these (name) and, obviously, when a spelling mistake begged for correction, because this is the field in flow.xml, any change immediately broke the processor.
See Processor PropertyDescriptor name vs. displayName below.
Today I was experiencing the difficulty of writing tests for a NiFi processor only to learn that there are helps from NiFi for this. I found the test for the original, JSON processor example.
package rocks.nifi.examples.processors;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.apache.commons.io.IOUtils;
import org.junit.Test;
import static org.junit.Assert.assertTrue;
import org.apache.nifi.util.TestRunner;
import org.apache.nifi.util.TestRunners;
import org.apache.nifi.util.MockFlowFile;
public class JsonProcessorTest
{
@Test
public void testOnTrigger() throws IOException
{
// Content to be mock a json file
InputStream content = new ByteArrayInputStream( "{\"hello\":\"nifi rocks\"}".getBytes() );
// Generate a test runner to mock a processor in a flow
TestRunner runner = TestRunners.newTestRunner( new JsonProcessor() );
// Add properites
runner.setProperty( JsonProcessor.JSON_PATH, "$.hello" );
// Add the content to the runner
runner.enqueue( content );
// Run the enqueued content, it also takes an int = number of contents queued
runner.run( 1 );
// All results were processed with out failure
runner.assertQueueEmpty();
// If you need to read or do aditional tests on results you can access the content
List< MockFlowFile > results = runner.getFlowFilesForRelationship( JsonProcessor.SUCCESS );
assertTrue( "1 match", results.size() == 1 );
MockFlowFile result = results.get( 0 );
String resultValue = new String( runner.getContentAsByteArray( result ) );
System.out.println( "Match: " + IOUtils.toString( runner.getContentAsByteArray( result ) ) );
// Test attributes and content
result.assertAttributeEquals( JsonProcessor.MATCH_ATTR, "nifi rocks" );
result.assertContentEquals( "nifi rocks" );
}
}
What does it do? NiFi TestRunner mocks out the NiFi framework and creates all the underpinnings I was trying today to create. This makes it so that calls inside onTrigger() don't summarily crash. I stepped through the test (above) to watch it work. All the references to the TestRunner object are ugly and only to set up what the framework would create for the processor, but it does work.
Had to work through these problems...
java.lang.AssertionError: Processor has 2 validation failures: 'basename' validated against 'CCD_Sample' is invalid because 'basename' is not a supported property 'doctype' validated against 'XML' is invalid because 'doctype' is not a supported property
—these properties don't even exist.
Caused by: java.lang.IllegalStateException: Attempting to Evaluate Expressions but PropertyDescriptor[Path to Python Interpreter] indicates that the Expression Language is not supported. If you realize that this is the case and do not want this error to occur, it can be disabled by calling TestRunner.setValidateExpressionUsage(false)
—so I disabled it. However, when this error or something like it is issued in the debugger:
java.lang.AssertionError: Processor has 1 validation failures: 'property name' validated against 'property default value' is invalid because 'property name' is not a supported property
it's likely because you didn't add validation to the property when defined:
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
Anyway, let's keep going...
Then, I reached the session.read() bit which appeared to execute, but processing never returned. So, I killed it, set a breakpoint on the session.write(), and relaunched. It got there. I set a breakpoint on the while( ( line = reply.readLine() ) != null ) and it got there. I took a single step more and, just as before, processing never returned.
Then I break-pointed out.write() and the first call to session.putAttribute() and relaunched. Processing never hit those points.
Will continue this tomorrow.
I want to solve my stream problems in python-filter. Note that the source code to GetFile is not a good example of what I'm trying to do because I'm getting the data to work on from (the session.read()) stream, passing it to the Python filter, then reading it back and spewing it down (the session.write()) output stream. For the (session.read()) input stream, ...
...maybe switch from readLine() to a byte-by-byte processing? But, all the examples in all kinds of situations (HTTP, socket, file, etc.) are using readLine().
The old Murphism about a defective appliance demonstrated to a competent technician will fail to fail applies here. My code was actually working. What was making me think it wasn't? Uh, well, for one thing, all the flowfile = session.putAttributes( flowfile, ... ) calls were broken for the same reason (higher up yesterday) other properties stuff wasn't.
Where am I?
I had to append "quit" to the end of my test data because that's the only way to tell the Python script that I'm done sending data.
So, I asked Nathan, who determined using a test:
import sys
while True:
input = sys.stdin.readline().strip()
if input == '':
break
upperCase = input.upper()
print( upperCase )
master ~/dev/python-filter $ echo "Blah!" | python poop.py
BLAH!
master ~/dev/python-filter $
...that checking the return from sys.stdin.readline() for being zero-length tells us to drop out of the read loop. But, this doesn't work in my code! Why?
I reasoned that in my command-line example, the pipe is getting closed. That's not happening in my NiFi code. So, I inserted a statement to close the pipe (see hilghted line below) as soon as finished writing what the input flowfile was offering:
session.read( flowfile, new InputStreamCallback()
{
/**
* There is probably a much speedier way than to read the flowfile line
* by line. Check it out.
*/
@Override
public void process( InputStream in ) throws IOException
{
BufferedReader input = new BufferedReader( new InputStreamReader( in ) );
String line;
while( ( line = input.readLine() ) != null )
{
output.write( line + "\n" );
output.flush();
}
output.close();
}
} );
| StandardValidators | Description |
|---|---|
| ATTRIBUTE_KEY_VALIDATOR | ? |
| ATTRIBUTE_KEY_PROPERTY_NAME_VALIDATOR | ? |
| INTEGER_VALIDATOR | is an integer value |
| POSITIVE_INTEGER_VALIDATOR | is an integer value above 0 |
| NON_NEGATIVE_INTEGER_VALIDATOR | is an integer value above -1 |
| LONG_VALIDATOR | is a long integer value |
| POSITIVE_LONG_VALIDATOR | is a long integer value above 0 |
| PORT_VALIDATOR | is a valid port number |
| NON_EMPTY_VALIDATOR | is not an empty string |
| BOOLEAN_VALIDATOR | is "true" or "false" |
| CHARACTER_SET_VALIDATOR | contains only valid characters supported by JVM |
| URL_VALIDATOR | is a well formed URL |
| URI_VALIDATOR | is a well formed URI |
| REGULAR_EXPRESSION_VALIDATOR | is a regular expression |
| ATTRIBUTE_EXPRESSION_LANGUAGE_VALIDATOR | is a well formed key-value pair |
| TIME_PERIOD_VALIDATOR | is of format duration time unit where duration is a non-negative integer and time unit is a supported type, one of { nanos, millis, secs, mins, hrs, days }. |
| DATA_SIZE_VALIDATOR | is a non-nil data size |
| FILE_EXISTS_VALIDATOR | is a path to a file that exists |
I'm still struggling to run tests after adding in all the properties I wish to support. I get:
'Filter Name' validated against 'filter.py' is invalid because 'Filter Name' is not a supported property
...and I don't understand why. Clearly, there's no testing of NiFi with corresponding failure cases. No one gives an explanation of this error, how to fix it, or what's involved in creating a proper, supported property. It's trial and error. I lucked out with PYTHON_INTERPRETER and FILTER_REPOSITORY.
However, I found that they all began to pass as soon as I constructed them with validators. I had left validation off because a) as inferred above I wonder about validation and b) at least the last four are optional.
Now, the code is running again. However,
final String doctype = flowfile.getAttribute( DOCTYPE ); final String pathname = flowfile.getAttribute( PATHNAME ); final String filename = flowfile.getAttribute( FILENAME ); final String basename = flowfile.getAttribute( BASENAME );
...gives me only FILENAME, because the NiFi TestRunner happens to set that one up. How does it know? The others return null, yet I've tried to set them. What's wrong is the corresondence between runner.setProperty() and the property and flowfile.getAttributes().
Let's isolate the properties handling (only) from the NiFi rocks example.
// JsonProcessor.java:
private List< PropertyDescriptor > properties;
public static final PropertyDescriptor JSON_PATH = new PropertyDescriptor.Builder()
.name( "Json Path" )
.required( true )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.build();
List< PropertyDescriptor > properties = new ArrayList<>();
properties.add( JSON_PATH );
this.properties = Collections.unmodifiableList( properties );
// JsonProcessorTest.java:
runner.setProperty( JsonProcessor.JSON_PATH, "$.hello" );
Hmmmm... I think there is a complete separation between flowfile attributes and processor properties. I've reworked all of that, and my code (still/now) works though there are unanswered questions.
runner.assertQueueEmpty() will fail (and stop testing) if there are any flowfiles left untransferred in the queue. Did you forget to transfer a flowfile? Did you lose your handle to a flowfile because you used the variable to point at another flowfile before you had transferred it? Etc.
NiFi logging example...
final ProcessorLog logger = getLogger();
String key = "someKey";
String value = "someValue";
logger.warn( "This is a warning message" );
logger.info( "This is a message with some interpolation key={}, value={}", new String[]{ key, value } );
My second NiFi processor at work.
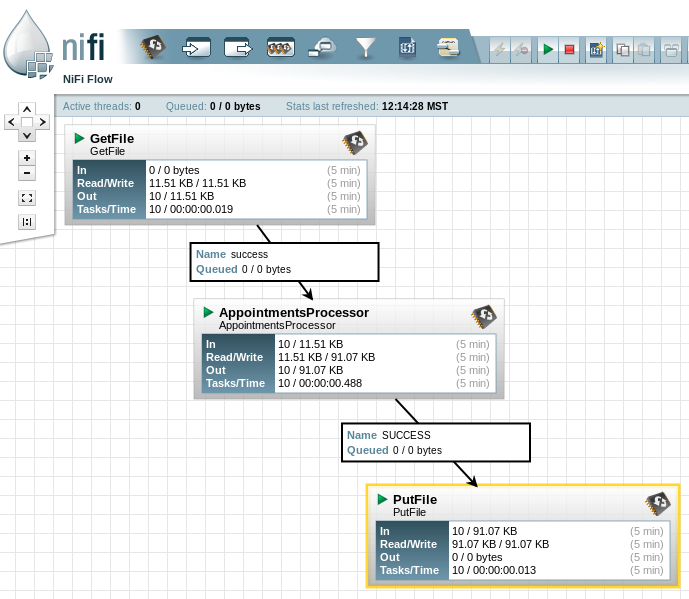
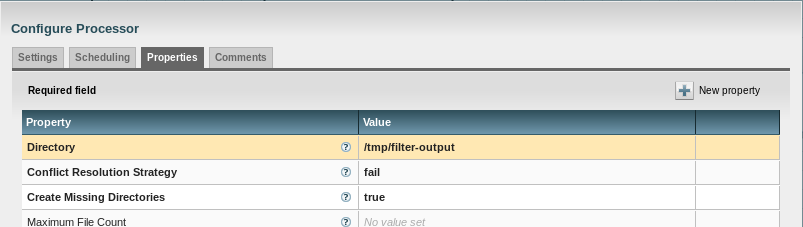
Documenting practical consumption of GetFile and PutFile processors (more or less "built-ins") of NiFi. These are the differences from default properties:
GetFile: Configure Processor
PutFile: Configure Processor
My own AppointmentsProcessor: Configure Processor
The UI sequence appears to be:
Looking to change my port number from 8080, the property is
nifi.web.http.port=8080
...and this is in ${NIFI_HOME}/conf/nifi.properties. Also of interest may be:
nifi.web.http.host nifi.web.https.host nifi.web.https.port
I'm testing actual NiFi set-ups for cda-breaker and cda-filter this morning. The former went just fine, but I'm going to document the setting up of a pipeline with the latter since I see I have not completely documented such a thing before.
I'm going to set up this:
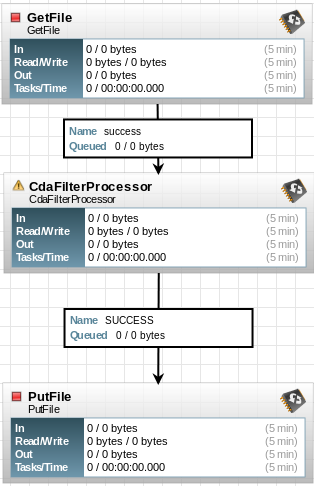
I accomplish this by clicking, dragging and dropping three new processors to the workspace. Here they are and their configurations:
Just the defaults...
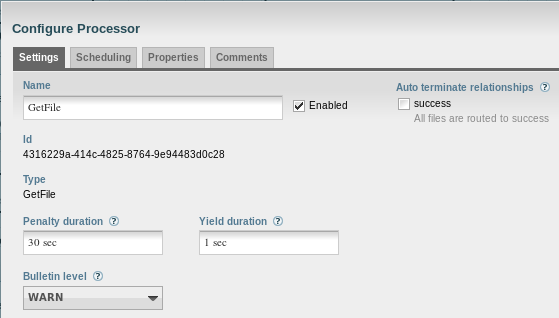
The 60 seconds keep the processor from firing over and over again (on the same file) before I can stop the pipeline: I only need it to fire once.
Get CDA_Sample1.xml out of /tmp/nifi-sources for the test.
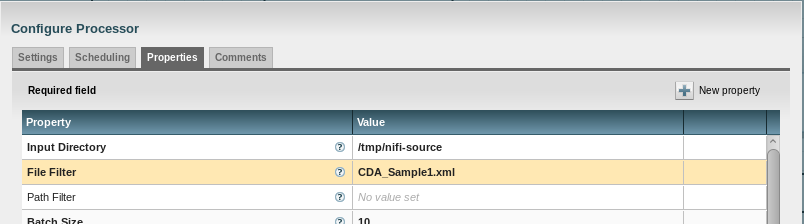
From GetFile, a connection to CdaFilterProcessor must be created for the success relationship (I only pass this file along if it exists):

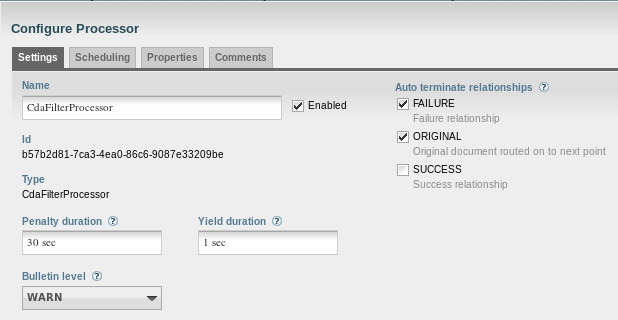
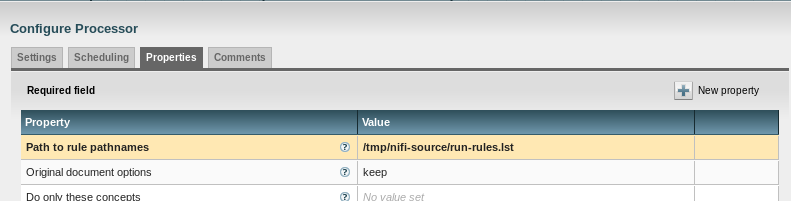
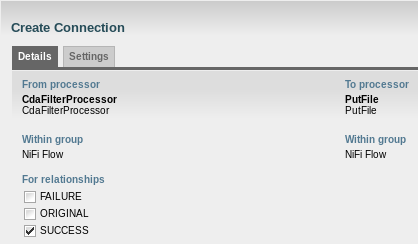
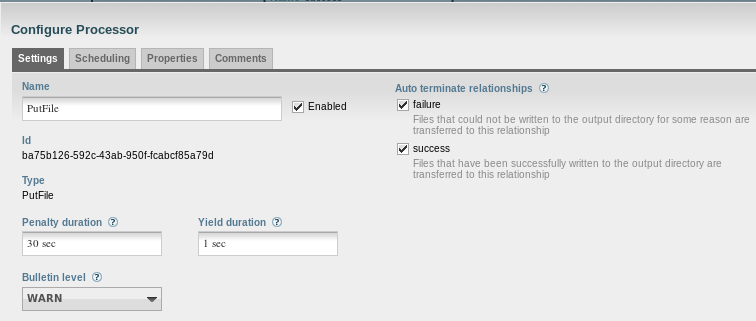
From CdaFilterProcessor, a connection to PutFile must be created for the original and success relationships:
(Of course, you must ensure that the source file, rules list and rules are in place for the test to have any chance of running.)
Once the three processors and two connections set up, you can turn the processors on in any order, but only once two are on at the same time, with data in the pipeline, will there be processing. Logically, GetFile if the first to light up.
Have left off busy with other stuff. I just found out that the reason additionalDetails.html doesn't work is because one's expected—and this isn't what the JSON example I used to get started does—to produce a JAR of one's processor, then only wrap that in the NAR.
Without that, your trip to right-click the processor, then choosing Usage is unrewarding.
Attacking NiFi attributes today. You get them off a flow file. However, to add an attribute, putAttribute() returns a new or wrapped flow file. The attribute won't be there if you look at the old flow file. In this snippet, we just forget the old flow file and use the new one under the same variable.
FlowFile flowfile = session.get(); String attribute-value = flowfile.getAttribute( "attribute-name" ); flowfile = session.putAttribute( flowfile, attributeName, attributeValue );
Please see Notes on Remote Debugging in Apache Nifi.
An exception that is not handled by the NiFi processor is therefore handled by the framework by doing a session roll-back and administrative yield. The flowfile is put back into the queue whence it was taken before the exception. It will continue to be submitted to the processor though the processor will slow down (because yielding). Once solution is to fix the processor to catch then gate failure down a relationship.
Got "DocGenerator Unable to document: class xyz / NullPointerException" reported in nifi-app.log
This occurs (at least) when your processor's relationships field (and the return from getRelationships()) is null.
2016-04-14 14:23:26,529 WARN [main] o.apache.nifi.documentation.DocGenerator Unable to document: class com.etretatlogiciels.nifi.processor.HeaderFooterIdentifier
java.lang.NullPointerException: null
at org.apache.nifi.documentation.html.HtmlProcessorDocumentationWriter.writeRelationships(HtmlProcessorDocumentationWriter.java:200) ~[nifi-documentation-0.4.1.jar:0.4.1]
at org.apache.nifi.documentation.html.HtmlProcessorDocumentationWriter.writeAdditionalBodyInfo(HtmlProcessorDocumentationWriter.java:47) ~[nifi-documentation-0.4.1.jar:0.4.1]
at org.apache.nifi.documentation.html.HtmlDocumentationWriter.writeBody(HtmlDocumentationWriter.java:129) ~[nifi-documentation-0.4.1.jar:0.4.1]
at org.apache.nifi.documentation.html.HtmlDocumentationWriter.write(HtmlDocumentationWriter.java:67) ~[nifi-documentation-0.4.1.jar:0.4.1]
at org.apache.nifi.documentation.DocGenerator.document(DocGenerator.java:115) ~[nifi-documentation-0.4.1.jar:0.4.1]
at org.apache.nifi.documentation.DocGenerator.generate(DocGenerator.java:76) ~[nifi-documentation-0.4.1.jar:0.4.1]
at org.apache.nifi.NiFi.(NiFi.java:123) [nifi-runtime-0.4.1.jar:0.4.1]
at org.apache.nifi.NiFi.main(NiFi.java:227) [nifi-runtime-0.4.1.jar:0.4.1]
Here's how to document multiple dynamic properties. For only one, just use @DynamicProperty alone.
@SideEffectFree
@Tags( { "SomethingProcessor" } )
@DynamicProperties( {
@DynamicProperty(
name = "section-N.name",
value = "Name",
supportsExpressionLanguage = false,
description = "Add the name to identify a section."
+ " N is a required integer to unify the three properties especially..."
+ " Example: \"section-1.name\" : \"illness\"."
),
@DynamicProperty(
name = "section-N.pattern",
value = "Pattern",
supportsExpressionLanguage = false,
description = "Add the pattern to identify a section."
+ " N is a required integer to unify the three properties especially..."
+ " Example: \"section-1.pattern\" : \"History of Illness\"."
),
@DynamicProperty(
name = "section-N.NLP",
value = "\"on\" or \"off\"",
supportsExpressionLanguage = false,
description = "Add whether to turn NLP on or off."
+ " N is a required integer to unify the three properties especially..."
+ " Example: \"section-1.nlp\" : \"on\"."
)
} )
public class SomethingProcessor extends AbstractProcessor
{
...
Need to set up NiFi to work from home. First, download the tarball containing binaries from Apache NiFi Downloads and explode it.
~/Downloads $ tar -zxf nifi-0.6.1-bin.tar.gz ~/Downloads $ mv nifi-0.6.1 ~/dev ~/Downloads $ cd ~/dev ~/dev $ ln -s ./nifi-0.6.1/ ./nifi
Edit nifi-0.6.1/conf/bootstrap.conf and add my username.
# Username to use when running NiFi. This value will be ignored on Windows. run.as=russ
Launch NiFi.
~/dev/nifi/bin $ ./nifi.sh start
Launch browser.
http://localhost:8080/nifi/
And there we are!
How to inject flow-file attributes:
TestRunner runner = TestRunners.newTestRunner( new VelocityTemplating() ); Map< String, String > flowFileAttributes = new HashMap<>(); flowFileAttributes.put( "name", "Velocity-templating Unit Test" ); // used in merging "Hello $name!" . . . runner.enqueue( DOCUMENT, flowFileAttributes ); . . .
If you install NiFi as a service, then wish to remove it, there are some files (these might not be the exact names) you'll need to remove:
Some useful comments on examing data during flow and debugging NiFi processors.
Andy LoPresto:
NiFi is intentionally designed to allow you to make changes on a very tight cycle while interacting with live data. This separates it from a number of tools that require lengthy deployment processes to push them to sandbox/production environments and test with real data. As one of the engineers says frequently, "NiFi is like digging irrigation ditches as the water flows, rather than building out a sprinkler system in advance."
Each processor component and queue will show statistics about the data they are processing and you can see further information and history by going into the Stats dialog of the component (available through the right-click context menu on each element).
To monitor actual data (such as the response of an HTTP request or the result of a JSON split), I'd recommend using the LogAttribute processor. You can use this processor to print the value of specific attributes, all attributes, flowfile payload, expression language queries, etc. to a log file and monitor the content in real-time. I'm not sure if we have a specific tutorial for this process, but many of the tutorials and videos for other flows include this functionality to demonstrate exactly what you are looking for. If you decide that the flow needs modification, you can also replay flowfiles through the new flow very easily from the provenance view.
One other way to explore the processors, is of course to write a unit test and evaluate the result compared to your expected values. This is more advanced and requires downloading the source code and does not use the UI, but for some more complicated usages or for people familiar with the development process, NiFi provides extensive flow mocking capabilities to allow developers to do this.
Matt Burgess:
As of at least 0.6.0, you can view the items in a queued connection. So for your example, you can have a GetHttp into a SplitJson, but don't start the SplitJson, just the GetHttp. You will see any flowfiles generated by GetHttp queued up in the success (or response?) connection (whichever you have wired to SplitJson). Then you can right-click on the connection (the line between the processors) and choose List Queue. In that dialog you can choose an element by clicking on the Info icon ('i' in a circle) and see the information about it, including a View button for the content.
The best part is that you don't have to do a "preview" run, then a "real" run. The data is in the connection's queue, so you can make alterations to your SplitJson, then start it to see if it works. If it doesn't, stop it and start the GetHttp again (if stopped) to put more data in the queue. For fine-grained debugging, you can temporarily set the Run schedule for the SplitJson to something like 10 seconds, then when you start it, it will likely only bring in one flow file, so you can react to how it works, then stop it before it empties the queue.
Joe Percivall:
Provenance is useful for replaying events but I also find it very useful for debugging processors/flows as well. Data Provenance is a core feature of NiFi and it allows you to see exactly what the FlowFile looked like (attributes and content) before and after a processor acted on it as well as the ability to see a map of the journey that FlowFile underwent through your flow. The easiest way to see the provenance of a processor is to right click on it and then click "Data provenance".
Before explaining how to work with templates and process groups, it's necessary to define certain visual elements of the NiFi workspace. I'm just getting around to this because my focus until now has been to write and debug custom processors for others' use.

Here's how to make a template in NiFi. Templates are used to reproduce work flows without having to rebuild them, from all their components and configuration, by hand. I don't know how yet to "carry" templates around between NiFi installations.
Go here for the best illustrated guide demonstrating Apache NiFi templates, or, better yet, go here: NiFi templating notes.
Here's a video on creating templates by the way. And here are the steps:

Here's how to consume an existing template in your NiFi workspace:

You can turn a template into a process group in order to push the detail of how it's built down to make your work flow simpler at the top level.
Here's a video on process groups.

Sometimes you already have a flow you want to transform into a process group.

You can zoom in (or out) on the process group. It looks like a processor because it performs the same function as a processor, only it does a lot more since it subsumes multiple processors.
However, a process group must have explicit input- and output ports in order to treat it as a processor:


...and the current installation too. Here's a video on exporting templates.


Note: if your template uses processors or other components that don't exist in the target NiFi installation (that your template is taken to), then it can be imported, but when attempting to use it in that installation, NiFi will issue an error (in a modeless alert).
This uses the Template Management dialog too.
Some NiFi notes here on logging...
Beginning in NiFi 1.0, it can be said that it used to be that NiFi logging would be done by each processor at the INFO level to say what it's doing for each flowfile. However, this became extremely abusive in terms of logging diskspace, so the the minimum level for processors was instead set to WARN. In conf/logback.xml this can be changed back by setting the log level of org.apache.nifi.processors.
Prior to 1.0, however, one saw this:
. . . <logger name="org.apache.nifi" level="INFO" /> . . .
Today I'm studying the NiFi ReST (NiFi API) which provides programmatic access to command and control of a NiFi instance (in real time). Specifically, I'm interested in monitoring, indeed, in obtaining an answer to questions like:
Also, I'm interested in:
But first, let's break this ReST control down by service. I'm not interested in all of these today, but since I've got the information in a list, here it is:
| Service | Function(s) |
|---|---|
| Controller | Get controller configuration, search the flow, manage templates, system diagnostics |
| Process Groups | Get the flow, instantiate a template, manage sub groups, monitor component status |
| Processors | Create a processor, set properties, schedule |
| Connections | Create a connection, set queue priority, update connection destination |
| Input Ports | Create an input port, set remote port access control |
| Output Ports | Create an output port, set remote port access control |
| Remote Process Groups | Create a remote group, enable transmission |
| Labels | Create a label, set label style |
| Funnels | Manage funnels |
| Controller Services | Manage controller services, update controller service references |
| Reporting Tasks | Manage reporting tasks |
| Cluster | View node status, disconnect nodes, aggregate component status |
| Provenance | Query provenance, search event lineage, download content, replay |
| History | View flow history, purge flow history |
| Users | Update user access, revoke accounts, get account details, group users |
Let me make a quick list of end-points that pique my interest and I'll try them out, make further notes, etc.
| Service | Verb | URI | Notes |
|---|---|---|---|
| Controller | GET | /controller/config | retrieve configuration |
| GET | /controller/counter | current counters |
Here's dynamic access to all of the service documentation: https://nifi.apache.org/docs/nifi-docs/rest-api/
If I'm accessing my NiFi canvas (flow) using http://localhost:8080/nifi, I use this URI to reach the ReST end-points:
http://localhost:8080/nifi-api/ service / end-point
For example, http://localhost:8080/nifi-api/controller/config returns (I'm running this against a NiFI flow that's got two flows of 3 and 2 processors with relationships between them that have sat for a couple of weeks unused) this:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<controllerConfigurationEntity>
<revision>
<clientId>87718998-e57b-43ac-9e65-15f2b8e0feaa</clientId>
</revision>
<config>
<autoRefreshIntervalSeconds>30</autoRefreshIntervalSeconds>
<comments></comments>
<contentViewerUrl>/nifi-content-viewer/</contentViewerUrl>
<currentTime>13:23:01 MDT</currentTime>
<maxEventDrivenThreadCount>5</maxEventDrivenThreadCount>
<maxTimerDrivenThreadCount>10</maxTimerDrivenThreadCount>
<name>NiFi Flow</name>
<siteToSiteSecure>true</siteToSiteSecure>
<timeOffset>-21600000</timeOffset>
<uri>http://localhost:8080/nifi-api/controller</uri>
</config>
</controllerConfigurationEntity>
I'm using the Firefox </> RESTED client. What about JSON? Yes, RESTED allows me to add Accept: application/json:
{
"revision":
{
"clientId": "f841561c-60c6-4d9b-a3ce-d2202789eef7"
},
"config":
{
"name": "NiFi Flow",
"comments": "",
"maxTimerDrivenThreadCount": 10,
"maxEventDrivenThreadCount": 5,
"autoRefreshIntervalSeconds": 30,
"siteToSiteSecure": true,
"currentTime": "14:06:18 MDT",
"timeOffset": -21600000,
"contentViewerUrl": "/nifi-content-viewer/",
"uri": "http://localhost:8080/nifi-api/controller"
}
}
I wanted to see the available processors in a list. I did this via: http://localhost:8080/nifi-api/controller/processor-types
However, I could not figure out what to supply as {processorId} to
controller/history/processors/{processorId}. I decided to use a processor
name:
http://localhost:8080/nifi-api/controller/history/processors/VelocityTemplating
This did the trick:
{
"revision":
{
"clientId": "86082d22-9fb2-4aea-86bc-efe062861d51"
},
"componentHistory":
{
"componentId": "VelocityTemplating",
"propertyHistory": {}
}
}
I notice that I can't see the name I give the processor. For example, I have a GetFile that I named Get PDF files from test fodder. I can't find any API that returns that.
Now, about instances of processors. The forum told me that, even if I'm not using any process groups, there is one process group for what I am using, namely root; this URI is highlighted below:
http://localhost:8080/nifi-api/controller/process-groups/root/status
{
"revision":
{
"clientId": "98d70ac0-476c-4c6b-bcbc-3ec91193d994"
},
"processGroupStatus":
{
"bulletins": [],
"id": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "NiFi Flow",
"connectionStatus":
[
{
"id": "f3a032d6-6bd1-4cc5-ab5e-8923e131c222",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "success",
"input": "0 / 0 bytes",
"queuedCount": "0",
"queuedSize": "0 bytes",
"queued": "0 / 0 bytes",
"output": "0 / 0 bytes",
"sourceId": "9929acf6-aac7-46d9-a0dd-f239d66e1594",
"sourceName": "Get PDFs from inbox",
"destinationId": "c396af51-2221-4bfd-ba31-5f4b5913b910",
"destinationName": "Generate XML from advance directives template"
},
{
"id": "e5ba7858-8301-4fd0-885e-6fb63b336e53",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "success",
"input": "0 / 0 bytes",
"queuedCount": "0",
"queuedSize": "0 bytes",
"queued": "0 / 0 bytes",
"output": "0 / 0 bytes",
"sourceId": "c396af51-2221-4bfd-ba31-5f4b5913b910",
"sourceName": "Generate XML from advance directives template",
"destinationId": "1af4a618-ca9b-4697-81b5-3ba1bbfaba6b",
"destinationName": "Put generated XMLs to output folder"
},
{
"id": "53e4a0e9-ce20-4e4d-84f3-d12504edeccc",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "success",
"input": "0 / 0 bytes",
"queuedCount": "3",
"queuedSize": "25.27 KB",
"queued": "3 / 25.27 KB",
"output": "0 / 0 bytes",
"sourceId": "4435c701-0719-4231-8867-671db08dd813",
"sourceName": "Get PDF files from test fodder",
"destinationId": "5f28baeb-b24c-4c3f-b6d0-c3284553d6ac",
"destinationName": "Put PDFs as in-box items"
}
],
"processorStatus":
[
{
"id": "c396af51-2221-4bfd-ba31-5f4b5913b910",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "Generate XML from advance directives template",
"type": "VelocityTemplating",
"runStatus": "Stopped",
"read": "0 bytes",
"written": "0 bytes",
"input": "0 / 0 bytes",
"output": "0 / 0 bytes",
"tasks": "0",
"tasksDuration": "00:00:00.000",
"activeThreadCount": 0
},
{
"id": "9929acf6-aac7-46d9-a0dd-f239d66e1594",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "Get PDFs from inbox",
"type": "GetInbox",
"runStatus": "Stopped",
"read": "0 bytes",
"written": "0 bytes",
"input": "0 / 0 bytes",
"output": "0 / 0 bytes",
"tasks": "0",
"tasksDuration": "00:00:00.000",
"activeThreadCount": 0
},
{
"id": "5f28baeb-b24c-4c3f-b6d0-c3284553d6ac",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "Put PDFs as in-box items",
"type": "PutInbox",
"runStatus": "Stopped",
"read": "0 bytes",
"written": "0 bytes",
"input": "0 / 0 bytes",
"output": "0 / 0 bytes",
"tasks": "0",
"tasksDuration": "00:00:00.000",
"activeThreadCount": 0
},
{
"id": "1af4a618-ca9b-4697-81b5-3ba1bbfaba6b",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "Put generated XMLs to output folder",
"type": "PutFile",
"runStatus": "Stopped",
"read": "0 bytes",
"written": "0 bytes",
"input": "0 / 0 bytes",
"output": "0 / 0 bytes",
"tasks": "0",
"tasksDuration": "00:00:00.000",
"activeThreadCount": 0
},
{
"id": "4435c701-0719-4231-8867-671db08dd813",
"groupId": "50e3886b-984d-4e90-a889-d46dc53c4afc",
"name": "Get PDF files from test fodder",
"type": "GetFile",
"runStatus": "Stopped",
"read": "0 bytes",
"written": "0 bytes",
"input": "0 / 0 bytes",
"output": "0 / 0 bytes",
"tasks": "0",
"tasksDuration": "00:00:00.000",
"activeThreadCount": 0
}
],
"processGroupStatus": [],
"remoteProcessGroupStatus": [],
"inputPortStatus": [],
"outputPortStatus": [],
"input": "0 / 0 bytes",
"queuedCount": "3",
"queuedSize": "25.27 KB",
"queued": "3 / 25.27 KB",
"read": "0 bytes",
"written": "0 bytes",
"output": "0 / 0 bytes",
"transferred": "0 / 0 bytes",
"received": "0 / 0 bytes",
"sent": "0 / 0 bytes",
"activeThreadCount": 0,
"statsLastRefreshed": "09:53:12 MDT"
}
}
This sort of hits the jackpot. What we see above are:
So, let's see if we can't dig into this stuff above using Python.
My Python's not as good as it was a year ago when I last coded in this language, but Python is extraordinarily useful, as compared to anything else (yeah, okay, I'm not too keen on Ruby as compared to Python and I'm certainly down on Perl) for writing these scripts. To write this in Java, you'd end up with fine software, but it is more work (to juggle the JSON-to-POJO transformation) and of course, a JAR isn't as brainlessly usable as your command-line is mucker than in a proper scripting language.
This illustrates a cautious traversal down to processor names (and types) which shows the way because there are countless additional tidbits to show like process group-wide status. Remember, this is a weeks-old NiFi installation that's just been sitting there. I've made no attempt to shake it around so that the status numbers get more interesting. Here's my first script:
import sys
import json
import globals
import httpclient
def main( argv ):
if( len( argv ) > 1 and argv[ 1 ] == '-d' or argv[ 1 ] == '--debug' ):
DEBUG = True
URI = globals.NIFI_API_URI( "controller" ) + 'process-groups/root/status'
print( 'URI = %s' % URI )
response = httpclient.get( URI )
jsonDict = json.loads( response )
print
print 'Keys back from request:'
print list( jsonDict.keys() )
processGroupStatus = jsonDict[ 'processGroupStatus' ]
print
print 'processGroupStatus keys:'
print list( processGroupStatus.keys() )
connectionStatus = processGroupStatus[ 'connectionStatus' ]
print
print 'connectionStatus keys:'
print connectionStatus
processorStatus = processGroupStatus[ 'processorStatus' ]
print
print 'processorStatus:'
print ' There are %d processors listed.' % len( processorStatus )
for processor in processorStatus:
print( ' (%s): %s' % ( processor[ 'type' ], processor[ 'name' ] ) )
if __name__ == "__main__":
if len( sys.argv ) <= 1:
args = [ 'first.py' ]
main( args )
sys.exit( 0 )
elif len( sys.argv ) >= 1:
sys.exit( main( sys.argv ) )
Output:
URI = http://localhost:8080/nifi-api/controller/process-groups/root/status
Keys back from request:
[u'processGroupStatus', u'revision']
processGroupStatus keys:
[u'outputPortStatus', u'received', u'queuedCount', u'bulletins', u'activeThreadCount', u'read', u'queuedSize', ...]
connectionStatus keys:
[{u'queuedCount': u'0', u'name': u'success', u'sourceId': u'9929acf6-aac7-46d9-a0dd-f239d66e1594', u'queuedSize': u'0 bytes' ...]
processorStatus:
There are 5 processors listed.
(VelocityTemplating): Generate XML from advance directives template
(GetInbox): Get PDFs from inbox
(PutInbox): Put PDFs as in-box items
(PutFile): Put generated XMLs to output folder
(GetFile): Get PDF files from test fodder
I'm convinced that Reporting Tasks, which are written very similarly to Processors, but not deployed like them (so, using a reporting task isn't so much a matter of tediously clicking and dragging boxes, but of enabling task reporting including custom task reporting for the whole flow or process group) are the best approach to monitoring. See also Re: Workflow monitoring/notifications.
(The second of the three NiFi architectural components is the Controller Service.)
The NiFi ReST end-points are very easy to use, but there is some difficulty in their semantics which appear a bit random still to my mind. The NiFi canvas or web UI is built atop these end-points (of course) and It is possible to follow what's happening using the Developer tools in your browser (Firefox: Developer Tools → Network, then click desired method to see URI, etc.). I found that a little challenging because I've been pretty much a back-end guy who's never used the browser developer intensively.
I found it very easy, despite not being a rockstar Python guy, to write simple scripts to hit NiFi. And I did. However, realize that the asynchrony of this approach presents a challenge given that a work flow can be very dynamic. Examining something in a NiFi flow from Python is like trying to inspect a flight to New York to see if your girlfriend is sitting next to your rival as it passes over Colorado, Nebraska, Iowa, etc. It's just not the best way. The ids of individual things you're looking for are not always easily ascertained and can change as the plane transits from Nebraska to Iowa to Illinois. Enabling task report or even writing a custom reporting task and enabling that strikes me as the better solution though it forces us to design or conceive of what we want to know up front. This isn't necessarily bad in the long-run.
Gain access to reporting tasks by clicking the Controller Settings in the Management Toolbar.
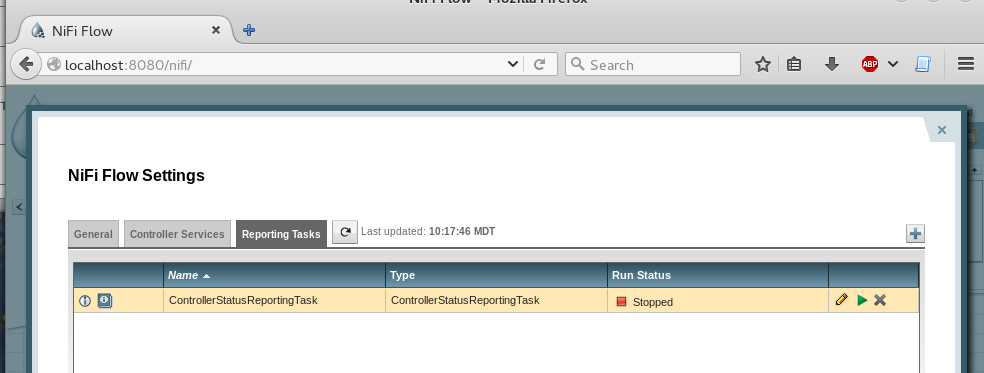
Here's a coded example, ControllerStatusReportingTask. The important methods to implement appear to be:
The onTrigger( ReportingContext context ) method is given access to reporting context which carries the following (need to investigate how this is helpful):
Yes, it just already exists, right? So use it? ControllerStatusReportingTask, that yields the following, which may be sufficient to most of our needs.
Information logged:
By default, the output from this reporting task goes to the NiFi log, but can be redirected elsewhere by modifying conf/logback.xml. (This would constitute a new logger, something like?)
<appender name="STATUS_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/nifi-status.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>./logs/nifi-status_%d.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
.
.
.
<logger name="org.apache.nifi.controller.ControllerStatusReportingTask" level="INFO" additivity="false">
<appender-ref ref="STATUS_FILE" />
</logger>
So, I think what we want is already rolled for us by NiFi and all we need do is:
Today, I followed these steps to reporting task happiness—as an experiment. I removed all log files in order to minimize the confusion and see differences in less space to look through.
fgrep reporting *.log yields:
nifi-app.log: org.apache.nifi.reporting.ganglia.StandardGangliaReporter || org.apache.nifi.nar.NarClassLoader[./work/nar/extensions/nifi-standard-nar-0.6.1.nar-unpacked] nifi-app.log: org.apache.nifi.reporting.ambari.AmbariReportingTask || org.apache.nifi.nar.NarClassLoader[./work/nar/extensions/nifi-ambari-nar-0.6.1.nar-unpacked] nifi-user.log:2016-07-14 09:49:09,509 INFO [NiFi Web Server-25] org.apache.nifi.web.filter.RequestLogger Attempting request for (anonymous) GET http://localhost:8080/nifi-api/controller/reporting-task-types (source ip: 127.0.0.1) nifi-user.log:2016-07-14 09:49:09,750 INFO [NiFi Web Server-70] org.apache.nifi.web.filter.RequestLogger Attempting request (ibid) nifi-user.log:2016-07-14 09:49:26,596 INFO [NiFi Web Server-24] org.apache.nifi.web.filter.RequestLogger Attempting request (ibid)
Even after waiting minutes, I see no difference when running the grep. However, I launch vim on nifi-app.log and see, here and there, stuff like:
2016-07-14 09:48:50,481 INFO [Timer-Driven Process Thread-1] c.a.n.c.C.Processors Processor Statuses: ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | Processor Name | Processor ID | Processor Type | Run Status | Flow Files In | Flow Files Out | Bytes Read | Bytes Written | Tasks | Proc Time | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | Generate XML from advance dire | c396af51-2221-4bfd-ba31-5f4b5913b910 | VelocityTemplating | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | | Get PDFs from inbox | 9929acf6-aac7-46d9-a0dd-f239d66e1594 | GetInbox | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | | Put PDFs as in-box items | 5f28baeb-b24c-4c3f-b6d0-c3284553d6ac | PutInbox | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | | Put generated XMLs to output f | 1af4a618-ca9b-4697-81b5-3ba1bbfaba6b | PutFile | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | | Get PDF files from test fodder | 4435c701-0719-4231-8867-671db08dd813 | GetFile | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ 2016-07-14 09:48:50,483 INFO [Timer-Driven Process Thread-1] c.a.n.c.C.Connections Connection Statuses: --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | Connection ID | Source | Connection Name | Destination | Flow Files In | Flow Files Out | FlowFiles Queued | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | 53e4a0e9-ce20-4e4d-84f3-d12504edeccc | Get PDF files from test fodder | success | Put PDFs as in-box items | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 9 / 75.82 KB (+9/+75.82 KB) | | f3a032d6-6bd1-4cc5-ab5e-8923e131c222 | Get PDFs from inbox | success | Generate XML from advance dire | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | | e5ba7858-8301-4fd0-885e-6fb63b336e53 | Generate XML from advance dire | success | Put generated XMLs to output f | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(I would figure out a little later that this is the start-up view before anthing's happened.)
<!-- Logger to redirect reporting task output to a different file. --> <logger name="org.apache.nifi.controller.ControllerStatusReportingTask" level="INFO" additivity="false"> <appender-ref ref="STATUS_FILE" /> </logger>
<!-- rolling appender for controller-status reporting task log. -->
<appender name="STATUS_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/nifi-status.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>./logs/nifi-status_%d.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
~/dev/nifi/logs $ ll
total 76
drwxr-xr-x 2 russ russ 4096 Jul 14 10:28 .
drwxr-xr-x 13 russ russ 4096 Jul 14 09:37 ..
-rw-r--r-- 1 russ russ 65016 Jul 14 10:29 nifi-app.log
-rw-r--r-- 1 russ russ 3069 Jul 14 10:28 nifi-bootstrap.log
-rw-r--r-- 1 russ russ 0 Jul 14 10:28 nifi-status.log
-rw-r--r-- 1 russ russ 0 Jul 14 10:28 nifi-user.log


2016-07-14 10:34:06,643 INFO [Timer-Driven Process Thread-1] c.a.n.c.C.Processors Processor Statuses: ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | Processor Name | Processor ID | Processor Type | Run Status | Flow Files In | Flow Files Out | Bytes Read | Bytes Written | Tasks | Proc Time | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | Get PDF files from test fodder | 4435c701-0719-4231-8867-671db08dd813 | GetFile | Stopped | 0 / 0 bytes (+0/+0 bytes) | 6 / 50.54 KB (+6/+50.54 KB) | 50.54 KB (+50.54 KB) | 50.54 KB (+50.54 KB) | 2 (+2) | 00:00:00.056 (+00:00:00.056) | | Put PDFs as in-box items | 5f28baeb-b24c-4c3f-b6d0-c3284553d6ac | PutInbox | Stopped | 6 / 50.54 KB (+6/+50.54 KB) | 0 / 0 bytes (+0/+0 bytes) | 50.54 KB (+50.54 KB) | 0 bytes (+0 bytes) | 1 (+1) | 00:00:00.014 (+00:00:00.014) | | Generate XML from advance dire | c396af51-2221-4bfd-ba31-5f4b5913b910 | VelocityTemplating | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | | Get PDFs from inbox | 9929acf6-aac7-46d9-a0dd-f239d66e1594 | GetInbox | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | | Put generated XMLs to output f | 1af4a618-ca9b-4697-81b5-3ba1bbfaba6b | PutFile | Stopped | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 bytes (+0 bytes) | 0 bytes (+0 bytes) | 0 (+0) | 00:00:00.000 (+00:00:00.000) | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 2016-07-14 10:34:06,644 INFO [Timer-Driven Process Thread-1] c.a.n.c.C.Connections Connection Statuses: -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | Connection ID | Source | Connection Name | Destination | Flow Files In | Flow Files Out | FlowFiles Queued | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | f3a032d6-6bd1-4cc5-ab5e-8923e131c222 | Get PDFs from inbox | success | Generate XML from advance dire | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | | e5ba7858-8301-4fd0-885e-6fb63b336e53 | Generate XML from advance dire | success | Put generated XMLs to output f | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | 0 / 0 bytes (+0/+0 bytes) | | 53e4a0e9-ce20-4e4d-84f3-d12504edeccc | Get PDF files from test fodder | success | Put PDFs as in-box items | 6 / 50.54 KB (+6/+50.54 KB) | 6 / 50.54 KB (+6/+50.54 KB) | 0 / 0 bytes (+0/+0 bytes) | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
What failed is getting the reported status into nifi-status.log. What succeeded is, just as was working before, getting controller status.
I got a response out of [email protected] that this was a reported bug and it's been
fixed in 0.7.0 and 1.0.0. Also note that %logging{40} is some log-back incantation to
affect the package name such that a name like
org.nifi.controller.ControllerStatusReportingTask becomes
o.n.c.ControllerStatusReportingTask. (See "Pattern Layouts" at
Chapter 6: Layouts.)
I upgraded my NiFi version to 0.7.0 at home and at the office.
I need to take time out to grok this.
${filename:toUpper()}
public static final PropertyDescriptor ADD_ATTRIBUTE = new PropertyDescriptor
.Builder()
.name( "Add Attribute" )
.description( "Example Property" )
.required( true )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.expressionLanguageSupported( true )
.build();
Map< String, String > values = new HashMap<>(); FlowFile flowFile = session.get(); PropertyDescriptor property = context.getProperty( ADD_ATTRIBUTE ); values.put( "hostname", property.evaluateAttributeExpressions( flowFile ).getValue() );
values.put( "hostname", flowFile.getAttribute( property.getValue() ) );
Hmmmm... yeah, there's precious little written on this stuff that really corrals it. So, I wrote this (albeit non-functional) example using the information above plus what I already know about flowfiles, properties and attributes:
package com.etretatlogiciels;
import java.util.HashMap;
import java.util.Map;
import org.apache.nifi.components.PropertyDescriptor;
import org.apache.nifi.components.PropertyValue;
import org.apache.nifi.components.Validator;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.util.StandardValidators;
public class FunWithNiFiProperties
{
private static final PropertyDescriptor EL_HOSTNAME = new PropertyDescriptor
.Builder()
.name( "Hostname (supporting EL)" )
.description( "Hostname property that supports NiFi Expression Language syntax"
+ "This is the name of the flowfile attribute to expect to hold the hostname" )
.required( false )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.expressionLanguageSupported( true ) // !
.build();
private static final PropertyDescriptor HOSTNAME = new PropertyDescriptor
.Builder()
.name( "Hostname" )
.description( "Hostname property that doesn't support NiFi Expression Language syntax."
+ "This is the name of the flowfile attribute to expect to hold the hostname" )
.required( false )
.addValidator( Validator.VALID )
.build();
// values will end up with a map of relevant data, names and values...
private Map< String, String > values = new HashMap<>();
/**
* Example of getting a hold of a property value via what the property value evaluates to
* including what not evaluating it as an expression yields.
*/
private void expressionLanguageProperty( final ProcessContext context, final ProcessSession session )
{
FlowFile flowFile = session.get();
PropertyValue property = context.getProperty( EL_HOSTNAME );
String value = property.getValue(); // (may contain expression-language syntax)
// what's our property and its value?
values.put( EL_HOSTNAME.getName(), value );
// is there a flowfile attribute of this precise name (without evaluating)?
// probably won't be a valid flowfile attribute if contains expression-language syntax...
values.put( "hostname", flowFile.getAttribute( value ) );
// -- or --
// get NiFi to evaluate the possible expression-language of the property as a flowfile attribute name...
values.put( "el-hostname", property.evaluateAttributeExpressions( flowFile ).getValue() );
}
/**
* Example of getting a hold of a property value the normal way, that is, not involving
* any expression syntax.
*/
private void normalProperty( final ProcessContext context, final ProcessSession session )
{
FlowFile flowFile = session.get();
PropertyValue property = context.getProperty( HOSTNAME );
String value = property.getValue(); // (what's in HOSTNAME)
// what's our property and its value?
values.put( HOSTNAME.getName(), value );
// is there a flowfile attribute by this precise name?
values.put( "hostname-attribute-on-flowfile", flowFile.getAttribute( value ) );
}
}
This is all I think I know so far:
Yesterday, I finally put together a tiny example of a full, custom NiFi project minus additionalDetails.html—for that, look in the notes on the present page). See A simple NiFi processor project.
Here's one for your gee-whiz collection: if you do
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
FlowFile flowfile = session.get();
.
.
.
someMethod( session );
...NiFi has removed the flowfile from the session's processorQueue and a subsequent call:
void someMethod( final ProcessSession session )
{
FlowFile flowfile = session.get();
...will produce a null flowfile. This is an interesting side-effect.
In what situation would onTrigger() get called if there is no flowfile?
This can happen for a few reasons. Because the processor has...
The main reason is the third. If you have multiple concurrent tasks, Thread 1 can determine that there is 1 flowfile queued. Thread 2 then determines that there is one flowfile queued. Both threads call onTrigger(), thread 1 gets the flowfile, and thread 2 gets nothing (null).
Is there a best practice for keeping a backup of data flows, assuming using flow.xml.gz and configuration files, it's possible to restore NiFi in case of any failure? Is it possible simply to "drop" this file into a new NiFi installation or should templates be used in development that get imported into production?
It's a good idea to back up flow.xml.gz and configuration files. But distinguish between using these backups to recreate an equivalent new NiFi installation and attempting to reset the state of the existing one. The difference is the live data in the flow, in the provenance repository, in state variables, etc.: Restoring a flow definition that doesn't match (or no longer matches) your content and provenance data may have unexpected results for you and for systems connecting with the NiFi installation. NiFi tries hard to handle these changes smoothly, but it isn't a magic time machine.
Deploying flow.xml.gz can work, especially when deployed with configuration files that reference IDs in the flow (like authorizations.xml) or the nifi.sensitive.props.key setting, and others. But if you overwrite a running flow, you will still have data migration problems.
Templates are the current recommended best practice for deployment. They provide:
Is there a way to predeploy templates to the template directory and have NiFi can recognize them?
Templates have been polished quite a bit to be more deterministic and source-control friendly so they are an ideal artifact to be versioned and kept in source-control repository.
When NiFi starts up, it looks in conf/templates (by default—this directory can be changed in nifi.properties). It looks for any file that has a suffix of .template or .xml so be sure the files are named properly. If starting a cluster, ensure all nodes in the cluster have these same templates or the latter will not show up.
Here's a small, complete example of a processor that translates attributes names or removes attributes. I found UpdateAttributes to be overly complicated and hard to use.
package com.etretatlogiciels.nifi.attributes;
import java.util.ArrayList;
import java.util.List;
public class NiFiStandardAttributes
{
public static final List< String > FLOWFILE_ATTRIBUTES;
static
{
FLOWFILE_ATTRIBUTES = new ArrayList<>( 5 );
FLOWFILE_ATTRIBUTES.add( "filename" );
FLOWFILE_ATTRIBUTES.add( "uuid" );
FLOWFILE_ATTRIBUTES.add( "path" );
}
public static final int FLOWFILE_ATTRIBUTE_COUNT = FLOWFILE_ATTRIBUTES.size();
}
package com.etretatlogiciels.nifi.processor;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import org.junit.After;
import org.junit.Before;
import org.junit.Rule;
import org.junit.Test;
import org.junit.rules.TestName;
import static org.junit.Assert.assertTrue;
import static org.junit.Assert.assertNull;
import static org.junit.Assert.assertNotNull;
import org.apache.nifi.util.MockFlowFile;
import org.apache.nifi.util.TestRunner;
import org.apache.nifi.util.TestRunners;
import com.etretatlogiciels.nifi.attributes.NiFiStandardAttributes;
import com.etretatlogiciels.testing.TestUtilities;
/**
* @author Russell Bateman
* @since September 2016
*/
public class TranslateAttributeNamesTest
{
// @formatter:off
@Rule public TestName name = new TestName();
@Before public void setUp() throws Exception { TestUtilities.setUp( name ); }
@After public void tearDown() throws Exception { }
private static final boolean VERBOSE = true;//TestUtilities.VERBOSE;
private static final String TRANSLATE_JSON ="{"
+ " \"inner-MIME\" : \"mime-type\","
+ " \"lose-this\" : \"\","
+ " \"lose-this-too\" : null"
+ "}";
@Test
public void testBasic()
{
TestRunner runner = TestRunners.newTestRunner( new TranslateAttributeNames() );
final int ONE = 1;
final String CONTENTS = "This is a test whose flowfile contents are insignificant!";
final InputStream MESSAGE = new ByteArrayInputStream( CONTENTS.getBytes() );
runner.setProperty( TranslateAttributeNames.TRANSLATIONS, TRANSLATE_JSON );
Map< String, String > flowFileAttributes = new HashMap<>();
flowFileAttributes.put( "testname", "X12 Message Router Unit Test" );
flowFileAttributes.put( "inner-MIME", "application/pdf" );
flowFileAttributes.put( "lose-this", "" );
flowFileAttributes.put( "lose-this-too", null );
flowFileAttributes.put( "dont-touch-this-one", "Don't touch this attribute!" );
if( VERBOSE )
{
System.out.println( "Attributes on the original flowfile:" );
Map< String, String > sortedAttributes = new TreeMap<>( flowFileAttributes );
for( Map.Entry< String, String > attribute : sortedAttributes.entrySet() )
System.out.println( " " + attribute.getKey() + " = " + attribute.getValue() );
}
runner.setValidateExpressionUsage( false );
runner.enqueue( MESSAGE, flowFileAttributes );
runner.run( ONE );
runner.assertQueueEmpty();
List< MockFlowFile > results = runner.getFlowFilesForRelationship( TranslateAttributeNames.SUCCESS );
MockFlowFile result = results.get( 0 );
String actual = new String( runner.getContentAsByteArray( result ) );
if( VERBOSE )
{
System.out.println( "Surviving flowfile contents:" );
System.out.println( " " + actual );
System.out.println( "Attributes surviving on the flowfile:" );
Map< String, String > sortedAttributes = new TreeMap<>( result.getAttributes() );
for( Map.Entry< String, String > attribute : sortedAttributes.entrySet() )
{
String key = attribute.getKey();
if( !NiFiStandardAttributes.FLOWFILE_ATTRIBUTES.contains( key ) )
System.out.println( " " + key + " = " + attribute.getValue() );
}
}
assertTrue( "Flowfile contents changed", actual.equals( CONTENTS ) );
String mimeType = result.getAttribute( "mime-type" );
assertNotNull( "Attribute \"inner-MIME\" was not renamed", mimeType );
assertTrue( "Attribute \"inner-MIME\" was not renamed", mimeType.equals( "application/pdf" ) );
String dontTouchThisOne = result.getAttribute( "dont-touch-this-one" );
assertNotNull( "Attribute \"dont-touch-this-one\" did not survive", result.getAttribute( "dont-touch-this-one" ) );
assertTrue( "Attribute \"dont-touch-this-one\" did not survive untouched",
dontTouchThisOne.equals( "Don't touch this attribute!" ) );
assertNull( "Attribute \"lose-this\" was not dropped", result.getAttribute( "lose-this" ) );
assertNull( "Attribute \"lose-this-too\" was not dropped", result.getAttribute( "lose-this-too" ) );
}
}
package com.etretatlogiciels.nifi.processor;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import org.apache.nifi.annotation.behavior.SideEffectFree;
import org.apache.nifi.annotation.documentation.CapabilityDescription;
import org.apache.nifi.annotation.documentation.Tags;
import org.apache.nifi.components.PropertyDescriptor;
import org.apache.nifi.components.Validator;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.processor.AbstractProcessor;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.ProcessorInitializationContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.exception.ProcessException;
import com.etretatlogiciels.nifi.rel.StandardRelationships;
import com.etretatlogiciels.utilities.StringUtilities;
/**
* Translate attribute names or even drop attributes altogether.
*
* {
* "attachment-filename" : "attachment",
* "disposition-encoding" : "encoding",
* "disposition-type" : null,
* "inner-MIME" : "mime_type",
* "inner-boundary" : "Donald Duck
* }
*
* @author Russell Bateman
* @since September 2016
*/
@SideEffectFree
@Tags( { "translateattributenames" } )
@CapabilityDescription( "Translate the names of attributes to new ones. The flowfile itself remains untouched." )
public class TranslateAttributeNames extends AbstractProcessor
{
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
FlowFile flowfile = session.get();
Map< String, String > translations = new Gson().fromJson( context.getProperty( TRANSLATIONS ).getValue(),
new TypeToken< Map< String, String > >(){ }.getType() );
// determine which attributes we'll be pushing onto the new flowfile...
Map< String, String > candidates = flowfile.getAttributes();
Map< String, String > attributes = new HashMap<>();
for( Map.Entry< String, String > attribute : candidates.entrySet() )
{
String key = attribute.getKey();
// do nothing because we're leaving the attribute as-is...
if( !translations.containsKey( key ) )
continue;
// remove this flowfile attribute because we're changing its name or dropping it...
flowfile = session.removeAttribute( flowfile, key );
String newKey = translations.get( key );
// we're dropping this attribute altogether...
if( StringUtilities.isEmpty( newKey ) || newKey.equals( "null" ) )
continue;
// here's the attribute under its new name...
attributes.put( translations.get( key ), attribute.getValue() );
}
flowfile = session.putAllAttributes( flowfile, attributes );
session.transfer( flowfile, SUCCESS );
}
private List< PropertyDescriptor > properties = new ArrayList<>();
private Set< Relationship > relationships = new HashSet<>();
@Override
public void init( final ProcessorInitializationContext context )
{
properties.add( TRANSLATIONS );
properties = Collections.unmodifiableList( properties );
relationships.add( SUCCESS );
relationships = Collections.unmodifiableSet( relationships );
}
@Override public List< PropertyDescriptor> getSupportedPropertyDescriptors() { return properties; }
@Override public Set< Relationship > getRelationships() { return relationships; }
//<editor-fold desc="Processor properties and relationships">
public static final PropertyDescriptor TRANSLATIONS = new PropertyDescriptor.Builder()
.name( "Translations" )
.description( "JSON detailing the name changes as key-value pairs where the value is the new name. Any value "
+ "that's null or <"<" will result in the attribute being dropped (not transmitted on the flowfile)." )
.required( false )
.addValidator( Validator.VALID )
.build();
public static final Relationship SUCCESS = StandardRelationships.SUCCESS;
//</editor-fold>
}
I had a question about cloning the input stream:
// under some condition, look into the flowfile contents to see if something's there...
session.read( flowfile, new InputStreamCallback()
{
@Override
public void process( InputStream( in ) throws IOException
{
// read from in...
}
} );
// then, later (and always) consume it (so, sometimes a second time):
session.read( flowfile, new InputStreamCallback()
{
@Override
public void process( InputStream( in ) throws IOException
{
// read from in (maybe again)...
}
} );
Wouldn't the second time be problematic since the stream contents have already been read?
I learned from Mark Payne that each time session.read() is called,
I'm getting a new InputStream that starts at the beginning of the flowfile.
How convenient!
Some observations on using GetFile:
I don't know why, after all these months, I'm still making mistakes like this. In two of my processors, which work when unit-tested, I keep getting:
Could not read from StandardFlowFileRecord
I tried a new way because likely the InputStream I'm caching is getting closed before I can use it again and this doesn't show up in the unit-test environment:
FlowFile flowfile = session.get();
flowfile = session.write( flowfile, new StreamCallback()
{
@Override
public void process( InputStream inputStream, OutputStream outputStream ) throws IOException
{
Base64Unroller unroller = new Base64Unroller( inputStream );
unroller.unroll();
InputStream in = unroller.getBase64Data();
int c;
for( ; ; )
{
c = in.read();
if( c == EOS || ( c == '\n' || c == '\r' ) )
break;
outputStream.write( c );
}
}
} );
session.transfer( flowfile, SUCCESS );
Flush with this better understanding of input- and output streams in NiFi, I'm going to see if this doesn't answer also the problem I have with Base64Decode.
It does solve my problem there: this is the answer to cases where I need both to read the input stream and write to an output stream.
I'm more interested here in detailing coding clauses I often write, but I don't write processors of all these sorts. Hilighted are lines important to consider.
final FlowFile flowfile = session.get();
session.read( flowfile, new InputStreamCallback()
{
@Override
public void process( InputStream in ) throws IOException
{
/* do stuff on the input stream */
FlowFile flowfile = session.create();
flowfile = session.write( flowfile, new OutputStreamCallback()
{
@Override public void process( OutputStream out ) throws IOException
{
out.write( /* the input from somewhere other than the flowfile */ );
}
});
final FlowFile flowfile = session.get();
flowfile = session.write( flowfile, new StreamCallback()
{
@Override public void process( InputStream inputStream, OutputStream outputStream )
throws IOException
{
InputStreamReader input = new InputStreamReader ( inputStream, "UTF-8" );
OutputStreamReader output = new OutputStreamReader( outputStream, "UTF-8" );
// read from input stream; write to output stream...
}
});
A list of repositories and what they do.
Got a link to great document I've never seen, Apache NiFi in Depth. Here are points of note. First, a list of repositories and what they do.
The provenance respository is where the history of each flowfile is stored. This involves the chain of custody for each piece of data. Each time a flowfile event (create, fork, clone, modify, etc.), a new provenance event is created. This event is a snapshot of the flowfile as it appeared and fit into the flow as it existed at that point in time. These events are held in the repository for a period of time after completion—controllable by configuration.
Because all of the flowfile attributes and pointers to content are kept in the provenance repository, not only the lineage or processing history of the data is visible, but the data itself and the data can be replayed from any point in the flow. When a down-stream processor appears not to have received data, data lineage can show exactly when it was delivered or indeed that it was never sent.
Flowing between processors is done using pass by reference. Flowfile content isn't actually streamed between processors, but only a reference to a flowfile is passed. When a flowfile is to be passed to two processors, it's cloned (content and attributes) and the references passed on.
I asked a question in the [email protected] forum.
"If I create flows for integration testing of multiple components (say, processors), where can I find the underlying files I can pick up, store and deploy to a fresh server with a fresh NiFi, then launch them on data (that I also deploy)?"
"I assumed that once I 'paint' my canvas with processors and relationships, it's harvestable in some form, in some .xml file somewhere, and easily transported to, then dropped into, a new NiFi installation on some server or host for running it. I assumed my testing would be thus configured, then kicked off somehow."
Andy LoPresto answered, "The 'flow' (the processors on the canvas and the relationships between them) is stored on disk as ${NIFI_HOME}/conf/flow.xml.gz [1]. You can also export selections from the flow as templates [2], along with a name and description, which can then be saved as XML files and loaded into a new instance of NiFi with (non-sensitive) configuration values and properties maintained. You may also be interested in the ongoing work to support the 'Software Development Lifecycle (SDLC)' or 'Development to Production Pipeline (D2P)' efforts to allow users to develop flows in testbed environments and 'promote' them through code control/repositories to QE/QA and then Production environments [3].
"If you are attempting to perform automated testing of flows or flow segments, you can do this with the test runner [4]. I would encourage you to store the flow in a template or full flow file (flow.xml.gz, not a 'flowfile') and load that during the test rather than programmatically instantiating and configuring each component and relationship in the test code, but you are able to do both. Also, be aware that the TestRunner is just that, and approximates/mocks some elements of the NiFi environment, so you should understand what decisions are being made behind the scenes to ensure that what is covered by the test is exactly what you expect."
I'm waiting on what [4] says about "automated testing of flows or flow segments." I did not understand from reading it that it said anything about that let alone offer a sample of how to inject flow.xml.
Googling, ... I did find a Hortonworks document on NiFi testing. However, it didn't talk about this either.
It did note, and I have often wondered about this because I had sort of reached a contrary conclusion about it, that running the processor from the test framework (run() method):
It pointed out that it only does all of the above as long as you do not pass an argument (like 1) to the run() method. This I had not known and I had reached the conclusion that it didn't run these other kinds of methods besides onTrigger().
The options for run() appear to be:
I got a later answer about someone else wanting to tackle all of this evoking the need to mock all sorts of things like database and wire answers for different processors. A sensation of hope headed toward the distant horizon filled me. It's a huge and thankless undertaking.

It's possible to annotate the NiFi canvas with labels, clicking and dragging a label to the the canvas and configuring it. These labels land behind anything you constructively design on the canvas (processors, relationships, funnels, etc.).
I have a hard time remembering how to view flowfile content in a queue, here are the steps:
(There is a better, more succinct treatment of this here, mostly code, but some of what is said here is useful.)
The following appear as observations to me. I've used dynamic properties before, but I've pretty much ignored doing them the way they're supposed to be done, I think. It's worth paying attention to everything in this list.
@Override
protected PropertyDescriptor getSupportedDynamicPropertyDescriptor( final String propertyDescriptorName )
{
.
.
.
}
@Tags( { "processor", "nifi" } )
@CapabilityDescription( "This is a processor" )
@DynamicProperty( name = "name",
value = "value",
description = "description" )
public class Processor extends AbstractProcessor
{
private List< PropertyDescriptor > properties;
.
.
.
public class Processor extends AbstractProcessor
{
private List< PropertyDescriptor > properties;
private volatile Set< String > dynamicPropertyNames = new HashSet<>();
@Override
protected void init( final ProcessorInitializationContext context )
{
final List< PropertyDescriptor > properties = new ArrayList<>();
properties.add( PROPERTY );
this.properties = Collections.unmodifiableList(properties);
}
.
.
.
@Override
protected PropertyDescriptor getSupportedDynamicPropertyDescriptor( final String propertyDescriptorName )
{
return new PropertyDescriptor.Builder()
.required( false )
.name( propertyDescriptorName )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.dynamic( true )
.build();
}
/**
* Called only when a NiFi user actually updates (changes) this property's value.
* @param descriptor
* @param oldValue --null if property had no previous value.
* @param newValue --null if property has been removed.
*/
@Override
public void onPropertyModified( final PropertyDescriptor descriptor, final String oldValue, final String newValue )
{
final Set newDynamicPropertyNames = new HashSet<>( this.dynamicPropertyNames );
if( newValue == null )
newDynamicPropertyNames.remove( descriptor.getName() );
else if( oldValue == null && descriptor.isDynamic() )
newDynamicPropertyNames.add( descriptor.getName() );
this.dynamicPropertyNames = Collections.unmodifiableSet( newDynamicPropertyNames );
}
@OnScheduled
public void onScheduled( final ProcessContext context )
{
for( final PropertyDescriptor descriptor : context.getProperties().keySet() )
{
if( descriptor.isDynamic())
{
getLogger().debug( "Dynamic property: {}", new Object[] { descriptor } );
.
.
.
(do stuff here)
}
}
}
For example, here every dynamic property is assumed to be a new attribute to be added to the resulting flowfile.
Notice that context.getProperties() contains both static and dynamic properties. This is so because all properties, both static and dynamic, set in the configuration are put by NiFi in that container. What distinguishes between them is isDynamic().
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.get();
.
.
.
for( Map.Entry< PropertyDescriptor, String > entry : context.getProperties().entrySet() )
{
if( entry.getKey().isDynamic() )
flowfile = session.putAttribute( flowfile, entry.getKey().getName(), entry.getValue() );
}
}
Every once in a while, I'm puzzled and rediscover that I've left stuff out making me scratch my head.
If you get this error in your log or debugger...
java.lang.AssertionError: Processor has 1 validation failures: property-name validated against value is invalid because property-name is not a supported property
..., you've likely left these methods out of your processor's implementation:
@Override public List< PropertyDescriptor > getSupportedPropertyDescriptors() { return properties; }
@Override public Set< Relationship > getRelationships() { return relationships; }
Here's how to get NiFi back up once you've removed a custom processor (yes, you lose your entire canvas):
~/dev/nifi/nifi-0.7.1/conf $ ll total 72 drwxr-xr-x. 3 russ russ 4096 Nov 2 14:45 . drwxr-xr-x. 14 russ russ 4096 Oct 21 09:07 .. -rw-r--r--. 1 russ russ 2129 Oct 13 17:54 authority-providers.xml -rw-r--r--. 1 russ russ 2530 Oct 13 17:54 authorized-users.xml -rw-r--r--. 1 russ russ 3241 Oct 13 17:54 bootstrap.conf -rw-r--r--. 1 russ russ 2119 Oct 13 17:15 bootstrap-notification-services.xml -rw-r--r--. 1 russ russ 1317 Nov 2 14:45 flow.xml.gz -rw-r--r--. 1 russ russ 7454 Oct 13 17:54 logback.xml -rw-r--r--. 1 russ russ 6089 Oct 13 17:54 login-identity-providers.xml -rw-r--r--. 1 russ russ 8571 Oct 13 17:54 nifi.properties -rw-r--r--. 1 russ russ 4603 Oct 13 17:54 state-management.xml drwxr-xr-x. 2 russ russ 4096 Oct 21 09:07 templates -rw-r--r--. 1 russ russ 1437 Oct 13 17:15 zookeeper.properties ~/dev/nifi/nifi-0.7.1/conf $ rm flow.xml.gz
(I can be embarrassingly stupid sometimes...)
You've configured nifi.properties to use port 9091.
nifi.web.http.port=9091
...but can't get NiFi to launch. The error from logs/nifi-bootstrap.log is:
~/dev/nifi/nifi-1.0.0/logs $ cat nifi-bootstrap.log
2016-11-04 11:32:32,217 INFO [main] o.a.n.b.NotificationServiceManager Successfully loaded the following 0 services: []
2016-11-04 11:32:32,221 INFO [main] org.apache.nifi.bootstrap.RunNiFi Registered no Notification Services for Notification Type NIFI_STARTED
2016-11-04 11:32:32,221 INFO [main] org.apache.nifi.bootstrap.RunNiFi Registered no Notification Services for Notification Type NIFI_STOPPED
2016-11-04 11:32:32,221 INFO [main] org.apache.nifi.bootstrap.RunNiFi Registered no Notification Services for Notification Type NIFI_DIED
2016-11-04 11:32:32,222 INFO [main] org.apache.nifi.bootstrap.Command Apache NiFi is not currently running
2016-11-04 11:32:35,684 INFO [main] o.a.n.b.NotificationServiceManager Successfully loaded the following 0 services: []
2016-11-04 11:32:35,687 INFO [main] org.apache.nifi.bootstrap.RunNiFi Registered no Notification Services for Notification Type NIFI_STARTED
2016-11-04 11:32:35,688 INFO [main] org.apache.nifi.bootstrap.RunNiFi Registered no Notification Services for Notification Type NIFI_STOPPED
2016-11-04 11:32:35,688 INFO [main] org.apache.nifi.bootstrap.RunNiFi Registered no Notification Services for Notification Type NIFI_DIED
2016-11-04 11:32:35,695 INFO [main] org.apache.nifi.bootstrap.Command Starting Apache NiFi...
2016-11-04 11:32:35,695 INFO [main] org.apache.nifi.bootstrap.Command Working Directory: /home/russ/dev/nifi/nifi-1.0.0
2016-11-04 11:32:35,696 INFO [main] org.apache.nifi.bootstrap.Command Command: /home/russ/dev/jdk1.8.0_25/bin/java -classpath /home/russ/dev/nifi/nifi-1.0.0/./conf:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-properties-loader-1.0.0.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/jcl-over-slf4j-1.7.12.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-api-1.0.0.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/logback-core-1.1.3.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/logback-classic-1.1.3.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-framework-api-1.0.0.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/jul-to-slf4j-1.7.12.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-documentation-1.0.0.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-runtime-1.0.0.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/slf4j-api-1.7.12.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-properties-1.0.0.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/bcprov-jdk15on-1.54.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/log4j-over-slf 4j-1.7.12.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/commons-lang3-3.4.jar:/home/russ/dev/nifi/nifi-1.0.0/./lib/nifi-nar-utils-1.0.0.jar -Dorg.apache.jasper.compiler.disablejsr199=true -Xmx512m -Xms512m -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000 -Dsun.net.http.allowRestrictedHeaders=true -Djava.net.preferIPv4Stack=true -Djava.awt.headless=true -XX:+UseG1GC -Djava.protocol.handler.pkgs=sun.net.www.protocol -Dnifi.properties.file.path=/home/russ/dev/nifi/nifi-1.0.0/./conf/nifi.properties -Dnifi.bootstrap.listen.port=33110 -Dapp=NiFi -Dorg.apache.nifi.bootstrap.config.log.dir=/home/russ/dev/nifi/nifi-1.0.0/logs org.apache.nifi.NiFi
2016-11-04 11:32:35,747 ERROR [NiFi logging handler] org.apache.nifi.StdErr ERROR: transport error 202: bind failed: Address already in use
2016-11-04 11:32:35,747 ERROR [NiFi logging handler] org.apache.nifi.StdErr ERROR: JDWP Transport dt_socket failed to initialize, TRANSPORT_INIT(510)
2016-11-04 11:32:35,747 ERROR [NiFi logging handler] org.apache.nifi.StdErr JDWP exit error AGENT_ERROR_TRANSPORT_INIT(197): No transports initialized [debugInit.c:750]
2016-11-04 11:32:35,747 INFO [NiFi logging handler] org.apache.nifi.StdOut FATAL ERROR in native method: JDWP No transports initialized, jvmtiError=AGENT_ERROR_TRANSPORT_INIT(197)
2016-11-04 11:32:36,739 INFO [main] org.apache.nifi.bootstrap.RunNiFi NiFi never started. Will not restart NiFi
And yet,
# lsof -i | grep 9091
...produces nothing for port 9091 (nor does netstat -lptu). So, port 9091 is not in use and yet the error leads one to believe that this is the problem.
It looks like remote debugging has been configured, which specifies a port that's obviously in use (8000). That happens in bootstrap.conf:
# Enable Remote Debugging java.arg.debug=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000
Still working on identifying how to create and store away in version control a process group.
Also looking into how we can hot-swap new or updated processors. Later, I'll get into an Agile write-up everyone agreed I'd do in the Core Team meeting yesterday afternoon.
We could set up a cluster for NiFi because rolling restarts are possible with individual instances in a cluster, that is, if I understand correctly, it's possible to take down one instance and update it, i.e.: restart it, without affecting the other though I wonder still right now if there's a way to throttle or somehow pause the instance so that it stops handling anything so that bouncing it has no ramifications like reprocessing jobs, etc.
To be noted too that the new/updated software isn't available until all nodes of the cluster have been updated and restarted.
When NiFi first starts up, the following directories (and files) are created:
Here's a flow to look at:
Unzipped (from flow.xml.gz), this flow looks like this:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<flowController>
<maxTimerDrivenThreadCount>10</maxTimerDrivenThreadCount>
<maxEventDrivenThreadCount>5</maxEventDrivenThreadCount>
<rootGroup>
<id>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</id>
<name>NiFi Flow</name>
<position x="0.0" y="0.0"/>
<comment/>
<processor>
<id>0c689901-1e21-4a89-af21-04ec13f1ca03</id>
<name>CreateFlowFile</name>
<position x="-27.0" y="-12.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.CreateFlowFile</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
<property>
<name>Content</name>
<value>This is a test of the Emergency Broadcast System.</value>
</property>
</processor>
<processor>
<id>c3daf696-11e7-4684-9e84-9f1aaedf15a6</id>
<name>RetryOperation</name>
<position x="281.0" y="86.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.RetryOperation</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
<property>
<name>Stop retrying operation when</name>
</property>
<property>
<name>Flowfile attribute name</name>
</property>
<property>
<name>Initial counter value</name>
<value>3</value>
</property>
<property>
<name>Retry cache-table TTL</name>
<value>10</value>
</property>
</processor>
<processor>
<id>e1d7c27f-e22f-480d-9d8d-591accbb7180</id>
<name>NoOperation</name>
<position x="639.0" y="272.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.NoOperation</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
</processor>
<processor>
<id>3bbe0931-dc54-490e-96cf-23f503f8915a</id>
<name>NoOperation</name>
<position x="278.0" y="272.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.NoOperation</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
</processor>
<connection>
<id>15af94b3-3db2-4bee-a7db-68869ad9bb86</id>
<name/>
<bendPoints>
<bendPoint x="234.5" y="229.0"/>
</bendPoints>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>3bbe0931-dc54-490e-96cf-23f503f8915a</sourceId>
<sourceGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</sourceGroupId>
<sourceType>PROCESSOR</sourceType>
<destinationId>c3daf696-11e7-4684-9e84-9f1aaedf15a6</destinationId>
<destinationGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</destinationGroupId>
<destinationType>PROCESSOR</destinationType>
<relationship>success</relationship>
<maxWorkQueueSize>0</maxWorkQueueSize>
<maxWorkQueueDataSize>0 MB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
<connection>
<id>c180a307-c0f5-48b5-8816-9abc54962b5b</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>c3daf696-11e7-4684-9e84-9f1aaedf15a6</sourceId>
<sourceGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</sourceGroupId>
<sourceType>PROCESSOR</sourceType>
<destinationId>e1d7c27f-e22f-480d-9d8d-591accbb7180</destinationId>
<destinationGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</destinationGroupId>
<destinationType>PROCESSOR</destinationType>
<relationship>Stop retrying</relationship>
<maxWorkQueueSize>0</maxWorkQueueSize>
<maxWorkQueueDataSize>0 MB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
<connection>
<id>ea3c8896-7775-4fce-83fe-8e95467c7811</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>0c689901-1e21-4a89-af21-04ec13f1ca03</sourceId>
<sourceGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</sourceGroupId>
<sourceType>PROCESSOR</sourceType>
<destinationId>c3daf696-11e7-4684-9e84-9f1aaedf15a6</destinationId>
<destinationGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</destinationGroupId>
<destinationType>PROCESSOR</destinationType>
<relationship>success</relationship>
<maxWorkQueueSize>0</maxWorkQueueSize>
<maxWorkQueueDataSize>0 MB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
<connection>
<id>f5739172-bf92-4ef8-a41b-b6e4dd363468</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>c3daf696-11e7-4684-9e84-9f1aaedf15a6</sourceId>
<sourceGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</sourceGroupId>
<sourceType>PROCESSOR</sourceType>
<destinationId>3bbe0931-dc54-490e-96cf-23f503f8915a</destinationId>
<destinationGroupId>9a3b3f31-d3fa-4e18-853f-f49510f48c2a</destinationGroupId>
<destinationType>PROCESSOR</destinationType>
<relationship>Retry operation</relationship>
<maxWorkQueueSize>0</maxWorkQueueSize>
<maxWorkQueueDataSize>0 MB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
</rootGroup>
<controllerServices/>
<reportingTasks/>
</flowController>
This file stores the flow which represents the processors on the canvas and the relationships between them. The record of processors (lines 10, 31, 62, 79 and 96) includes their properties, even sensitive ones (like passwords—though none here), as shown on lines 53-60 above, and their graphical position on the canvas (see lines 13, 34, etc. above).
Also highlighted above are the names of relationships that correspond to connections. Here's a second flow, this time with a process group:
|
Inside "MyProcessGroup"... 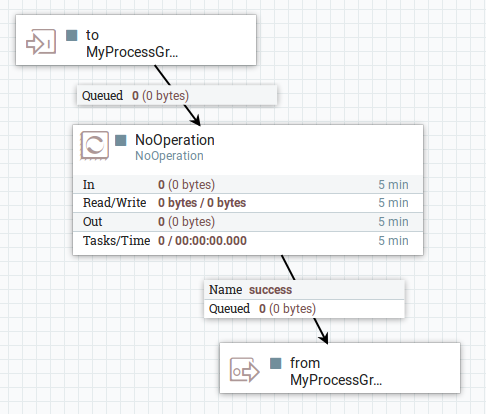
|
Unzipped (from flow.xml.gz), this flow looks like this:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<flowController encoding-version="1.0">
<maxTimerDrivenThreadCount>10</maxTimerDrivenThreadCount>
<maxEventDrivenThreadCount>5</maxEventDrivenThreadCount>
<rootGroup>
<id>746c58aa-0158-1000-08a8-9984ee3a72bc</id>
<name>NiFi Flow</name>
<position x="0.0" y="0.0"/>
<comment/>
<processor>
<id>74a80bc0-0158-1000-8699-37fc9ff670e4</id>
<name>CreateFlowFile</name>
<position x="252.0" y="4.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.CreateFlowFile</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
<property>
<name>Content</name>
<value>All good me must come to the aid of their country.</value>
</property>
</processor>
<processor>
<id>74a8e138-0158-1000-92f3-c6ec8781ba64</id>
<name>NoOperation</name>
<position x="249.0" y="601.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.NoOperation</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
</processor>
<processGroup>
<id>74a6c4bd-0158-1000-3de4-adbe359fb278</id>
<name>MyProcessGroup</name>
<position x="232.0" y="289.0"/>
<comment/>
<processor>
<id>74a70fd2-0158-1000-3d8e-645008570026</id>
<name>NoOperation</name>
<position x="285.0" y="184.0"/>
<styles/>
<comment/>
<class>com.etretatlogiciels.nifi.processor.NoOperation</class>
<maxConcurrentTasks>1</maxConcurrentTasks>
<schedulingPeriod>0 sec</schedulingPeriod>
<penalizationPeriod>30 sec</penalizationPeriod>
<yieldPeriod>1 sec</yieldPeriod>
<bulletinLevel>WARN</bulletinLevel>
<lossTolerant>false</lossTolerant>
<scheduledState>STOPPED</scheduledState>
<schedulingStrategy>TIMER_DRIVEN</schedulingStrategy>
<runDurationNanos>0</runDurationNanos>
</processor>
<inputPort>
<id>74a74ed5-0158-1000-76fc-eeb723a5f47a</id>
<name>to MyProcessGroup</name>
<position x="228.0" y="74.0"/>
<comments/>
<scheduledState>STOPPED</scheduledState>
</inputPort>
<outputPort>
<id>74a772d8-0158-1000-4916-01c5a8b496e9</id>
<name>from MyProcessGroup</name>
<position x="432.0" y="402.0"/>
<comments/>
<scheduledState>STOPPED</scheduledState>
</outputPort>
<connection>
<id>74a79d27-0158-1000-ecf5-2c3ae0360366</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>74a70fd2-0158-1000-3d8e-645008570026</sourceId>
<sourceGroupId>74a6c4bd-0158-1000-3de4-adbe359fb278</sourceGroupId>
<sourceType>PROCESSOR</sourceType>
<destinationId>74a772d8-0158-1000-4916-01c5a8b496e9</destinationId>
<destinationGroupId>74a6c4bd-0158-1000-3de4-adbe359fb278</destinationGroupId>
<destinationType>OUTPUT_PORT</destinationType>
<relationship>success</relationship>
<maxWorkQueueSize>10000</maxWorkQueueSize>
<maxWorkQueueDataSize>1 GB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
<connection>
<id>74a78f0c-0158-1000-a1f3-a3c2c8730ff2</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>74a74ed5-0158-1000-76fc-eeb723a5f47a</sourceId>
<sourceGroupId>74a6c4bd-0158-1000-3de4-adbe359fb278</sourceGroupId>
<sourceType>INPUT_PORT</sourceType>
<destinationId>74a70fd2-0158-1000-3d8e-645008570026</destinationId>
<destinationGroupId>74a6c4bd-0158-1000-3de4-adbe359fb278</destinationGroupId>
<destinationType>PROCESSOR</destinationType>
<relationship/>
<maxWorkQueueSize>10000</maxWorkQueueSize>
<maxWorkQueueDataSize>1 GB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
</processGroup>
<connection>
<id>74b5493a-0158-1000-617d-40ba69f7ad05</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>74a772d8-0158-1000-4916-01c5a8b496e9</sourceId>
<sourceGroupId>74a6c4bd-0158-1000-3de4-adbe359fb278</sourceGroupId>
<sourceType>OUTPUT_PORT</sourceType>
<destinationId>74a8e138-0158-1000-92f3-c6ec8781ba64</destinationId>
<destinationGroupId>746c58aa-0158-1000-08a8-9984ee3a72bc</destinationGroupId>
<destinationType>PROCESSOR</destinationType>
<relationship/>
<maxWorkQueueSize>10000</maxWorkQueueSize>
<maxWorkQueueDataSize>1 GB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
<connection>
<id>74a8a54b-0158-1000-7902-ac61947fd255</id>
<name/>
<bendPoints/>
<labelIndex>1</labelIndex>
<zIndex>0</zIndex>
<sourceId>74a80bc0-0158-1000-8699-37fc9ff670e4</sourceId>
<sourceGroupId>746c58aa-0158-1000-08a8-9984ee3a72bc</sourceGroupId>
<sourceType>PROCESSOR</sourceType>
<destinationId>74a74ed5-0158-1000-76fc-eeb723a5f47a</destinationId>
<destinationGroupId>74a6c4bd-0158-1000-3de4-adbe359fb278</destinationGroupId>
<destinationType>INPUT_PORT</destinationType>
<relationship>success</relationship>
<maxWorkQueueSize>10000</maxWorkQueueSize>
<maxWorkQueueDataSize>1 GB</maxWorkQueueDataSize>
<flowFileExpiration>0 sec</flowFileExpiration>
</connection>
</rootGroup>
<controllerServices/>
<reportingTasks/>
</flowController>
The two artifacts that are crucial to our ability to deploy are
Process groups are found inside flow.xml.gz, as shown above.
"NiFi's orientation is around continuous streams of data rather than starting and completing jobs.
"When you look at processors via the UI and you see the green start arrow or the red stopped square it is best to think about [those as meaning] 'this component is (or is not) scheduled to execute' rather than 'this is running or not running.' It is ok that they're scheduled to run. They're still not going to actually get triggered unless they need to be. If the [up-stream processor has no] data to send then [the next processor] won't actually be triggered to execute."
—Joe Witt
On a cluster node going down...
If a NiFi node dies and the disks on which its data are found are inaccessible by other NiFi instances (whether on the same or different hosts), then that data is not available until the situation is rectified. The way to achieve continuous availability is to set up the key repositories (content, flowfile and provenance) such that they can be remounted by another host. This is non-trivial. There has been a discussion of integrating management of this into NiFi itself.
Here's a somewhat random note on clustering by Andy LoPresto:
NiFi does not have a defined maximum cluster size. For the best performance, we usually recommend fewer than 10 nodes per cluster, but no more. If you have high performance needs, we have generally seen the best results with multiple smaller clusters than one large one. In this way, you can have hundreds of nodes processing the data in parallel, but the cluster administration overhead does not tax a single cluster coordinator to death.
Imagine a conf/flow.xml.gz that runs as soon as NiFi is started. However, imagine it hanging and the UI is unavailable to stop the processors, look around or otherwise look for the problem. What to do?
In conf/nifi.properties, there is nifi.flowcontroller.autoResumeState that can be set to false (the default is true) before restarting NiFi. Look for errors in logs/nifi-app.log.
Remember to set back to the default when finished. If any changes in debugging the problem are made to the flow, a new conf/flow.xml.gz will be generated with processors in a stopped state (or with other changes made when debugging) which may not be what is wanted.
To log what flowfile is getting passed out from each processor to understand what the processor has done to that flowfile, LogAttribute processor has a property, Log Payload, that can be set to true that you could use this at different points in your flow.
Another solution that will work without modifying a flow is to use NiFi's provenance feature from the UI. Right-click on a processor and select Data provenance, then pick an event and view the lineage graph. (Note that provenance in NiFi is typically configured to evaporate in order to save space, so there may be nothing to look at if you wait too long). From there you can look at the content of each event in the graph to see how it changed as it moved through the flow.
Rather than examining the lineage, you could clikc View Details (the "info" or question-mark icon to the left of the table record). Then switch to the Content tab to see the in-coming and out-going content at each step of provenance. Clicking Download will bring the raw output to your filesystem while View will open a content viewer in another window displaying the flowfile in various text formats.
One way to draw a user's attention is to use a standard log statement with proper level. This will issue a bulletin both on the processor (and visually indicate a note) as well as add it to a global list of bulletins. By default processors ignore anything lower than WARN, but this is adjustable in processor settings (right-click the processor in the UI, choose Configure, click the Settings tab and see Bulletin Level).
I saw a thread in the developers' forum discussing a counter and I wondered about using ProcessSession's counter in place of writing a special processor for Mat and Steve that counts documents:
void adjustCounter( String name, long delta, boolean immediate )
Adjusts counter data for the given counter name and takes care of registering
the counter if not already present, i.e.:
session.adjustCounter( "Counter", 1, false ); session.transfer( flowFile, SUCCESS );
I need to figure out where to see this counter. I discovered it in the NiFi Counters summary which is in a different place in the UI depending on the NiFi version (showing both at right). It lists the particulars including the individual passage of flowfiles through a processor that adjusts the count and also totals for all flowfiles through a processor that calls adjustCounter(). It's confusing if the processor is used over and over again in a flow because it shows up in the list.
Here's a listing in which I explicitly made this call, as coded just above, in Timer and ran through the flow illustrated above (yesterday).
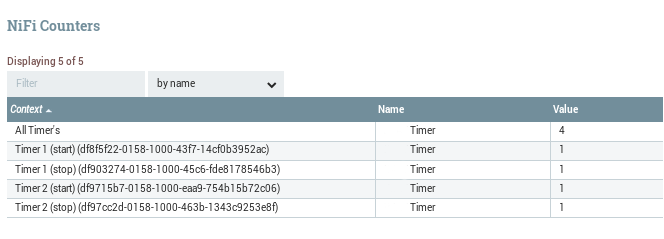
(The long ids in the list above are processor instance ids.)
However, if I remove this explicit call, nothing shows up in this list after running a flowfile completely through the four instances of Timer. So, some processor must explicitly make this call.
So, to interpret what's in the list above, note that:
To name the counter, a property could be used or the name of the counter could come from the processor's special name (as set in the Configure → Settings → Name field.
It remains to be seen which processors of our we wish to put a counter into and how we want to know to make the call.
# web properties nifi.web.http.port=9091
# Site to Site properties nifi.remote.input.secure=false nifi.remote.input.socket.port=9098
If transmission is disabled, as shown by the circle icon with a line through it on this processor at upper left, then right-click and enable it. This will not work if the remote instance of NiFi has not yet been a) properly configured and b) launched and working.
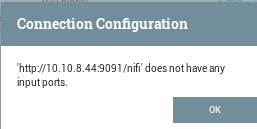
Skip to the next step to correct this.

Note, at this point, that even with this input port, you still cannot connect the local NiFi instance's CreateFlowFile (to the remote processor group).

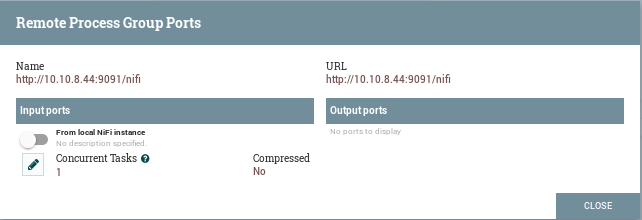
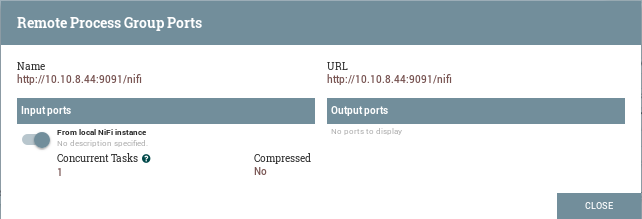
russ@nargothrond /tmp $ ls -lart . . . -rw-r--r-- 1 russ russ 70 Dec 13 11:06 1703060523504973 drwxrwxrwt 24 root root 4096 Dec 13 12:17 . russ@nargothrond /tmp $ cat 1703060523504973 This is a test of the Emergency Broadcast System. This is only a test.russ@nargothrond /tmp $
Note: site-to-site is a feature that's only available to input- and output ports in the root process group—not child process groups. Conceptually, if you want to push (remote) data into a child process group, you must create an input port at the root-level, then connect that input port to the child process group's input port.
I was trying to subject NiFi to the Java Flight Recorder (JFR). However, adding the needed arguments to conf/bootstrap.conf proved difficult. NiFi wasn't having them (as reported naively in the developers' forum).
There is no problem in NiFi per se. It was not really necessary to dig down into the code really because there's no problem there. It's just how java.arg.n is consumed that creates trouble. One must play around with the value of n when argument ordering is crucial. In the present case, I was able to turn on JFR using the following (in bold) in conf/bootstrap.conf:
#Set headless mode by default java.arg.14=-Djava.awt.headless=true # Light up the Java Flight Recorder... java.arg.32=-XX:+UnlockCommercialFeatures java.arg.31=-XX:+FlightRecorder java.arg.42=-XX:StartFlightRecording=duration=120m,filename=recording.jfr # Master key in hexadecimal format for encrypted sensitive configuration values nifi.bootstrap.sensitive.key=
The point was that -XX:+UnlockCommercialFeatures must absolutely precede the other two options. Because of these arguments passing through HashMap, some values of n will fail to sort an argument before others and the addition of other arguments might also come along and disturb this order. What I did here was by trial and error. I guess NiFi code could man-handle n in every case such that the order be respected. I'm guessing that my case is the only or one of the very rare times options are order-dependent. I wouldn't personally up-vote a JIRA to fix this.
My trial and error went pretty fast using this command line between reassigning instances of n for these arguments. It took me maybe 6 tries. (Script bounce-nifi.sh does little more than shut down, then start up NiFi, something I do a hundred times per day across at least two versions.)
~/dev/nifi/nifi-1.1.0/logs $ rm *.log ; bounce-nifi.sh 1.1.0 ; tail -f nifi-bootstrap.log
http://stackoverflow.com/questions/151238/has-anyone-ever-got-a-remote-jmx-jconsole-to-work
I'm trying to JMC to run the Flight Recorder (JFR) to profile NiFi on a remote server that doesn't offer a graphical environment on which to run JMC.
Here is what I'm supplying to the JVM (conf/bootstrap.conf) when I launch NiFi:
java.arg.90=-Dcom.sun.management.jmxremote=true java.arg.91=-Dcom.sun.management.jmxremote.port=9098 java.arg.92=-Dcom.sun.management.jmxremote.rmi.port=9098 java.arg.93=-Dcom.sun.management.jmxremote.authenticate=false java.arg.94=-Dcom.sun.management.jmxremote.ssl=false java.arg.95=-Dcom.sun.management.jmxremote.local.only=false java.arg.96=-Djava.rmi.server.hostname=10.10.10.92 (the IP address of my server running NiFi)
I did put this in /etc/hosts, though I doubt it's needed:
10.10.10.92 localhost
Then, upon launching JMC, I create a remote connection with these properties:
Host: 10.10.10.92 Port: 9098 User: (nothing) Password: (ibid)
Incidentally, if I click the Custom JMX service URL, I see:
service:jmx:rmi:///jndi/rmi://10.10.10.92:9098/jmxrmi
At some point, weeks later, this stopped working. I scratched my head. It turns out that I had run an Ansible script that activated iptables and I had to open port 9098 through the firewall created:
# iptables -A INPUT -p tcp --dport 9098 -j ACCEPT
Watching NiFi come up. In conf/nifi.properties, nifi.web.http.port=9091...
~/dev/nifi $ ps -ef | grep [n]ifi russ 27483 1 0 14:37 pts/4 00:00:00 /bin/sh ./nifi.sh start russ 27485 27483 2 14:37 pts/4 00:00:00 /home/russ/dev/jdk1.8.0_112/bin/java \ -cp /home/russ/dev/nifi/nifi-1.1.1/conf:/home/russ/dev/nifi/nifi-1.1.1/lib/bootstrap/* \ -Xms12m -Xmx24m \ -Dorg.apache.nifi.bootstrap.config.log.dir=/home/russ/dev/nifi/nifi-1.1.1/logs / -Dorg.apache.nifi.bootstrap.config.pid.dir=/home/russ/dev/nifi/nifi-1.1.1/run / -Dorg.apache.nifi.bootstrap.config.file=/home/russ/dev/nifi/nifi-1.1.1/conf/bootstrap.conf / org.apache.nifi.bootstrap.RunNiFi start russ 27508 27485 99 14:37 pts/4 00:00:21 /home/russ/dev/jdk1.8.0_112/bin/java / -classpath /home/russ/dev/nifi/nifi-1.1.1/./conf :/home/russ/dev/nifi/nifi-1.1.1/./lib/slf4j-api-1.7.12.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/nifi-documentation-1.1.1.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/nifi-nar-utils-1.1.1.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/log4j-over-slf4j-1.7.12.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/logback-core-1.1.3.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/jul-to-slf4j-1.7.12.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/jcl-over-slf4j-1.7.12.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/nifi-framework-api-1.1.1.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/nifi-properties-1.1.1.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/logback-classic-1.1.3.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/nifi-api-1.1.1.jar :/home/russ/dev/nifi/nifi-1.1.1/./lib/nifi-runtime-1.1.1.jar -Dorg.apache.jasper.compiler.disablejsr199=true / -Xmx512m / -Xms512m / -Dsun.net.http.allowRestrictedHeaders=true / -Djava.net.preferIPv4Stack=true / -Djava.awt.headless=true / -XX:+UseG1GC / -Djava.protocol.handler.pkgs=sun.net.www.protocol / -Dnifi.properties.file.path=/home/russ/dev/nifi/nifi-1.1.1/./conf/nifi.properties / -Dnifi.bootstrap.listen.port=38751 / -Dapp=NiFi / -Dorg.apache.nifi.bootstrap.config.log.dir=/home/russ/dev/nifi/nifi-1.1.1/logs / org.apache.nifi.NiFi ~ # netstat -lptu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 localhost:63342 *:* LISTEN 23923/java tcp 0 0 localhost:47060 *:* LISTEN 1876/GoogleTalkPlug tcp 0 0 gondolin:domain *:* LISTEN 1238/dnsmasq tcp 0 0 *:ssh *:* LISTEN 1124/sshd tcp 0 0 *:35353 *:* LISTEN 23923/java tcp 0 0 localhost:6942 *:* LISTEN 23923/java tcp 0 0 *:9091 *:* LISTEN 27508/java tcp 0 0 localhost:45608 *:* LISTEN 27508/java tcp 0 0 localhost:58634 *:* LISTEN 1876/GoogleTalkPlug tcp6 0 0 [::]:64628 [::]:* LISTEN 24068/java tcp6 0 0 [::]:ssh [::]:* LISTEN 1124/sshd tcp6 0 0 [::]:44155 [::]:* LISTEN 24068/java tcp6 0 0 localhost:38751 [::]:* LISTEN 27485/java udp 0 0 *:mdns *:* 919/avahi-daemon: r udp 0 0 gondolin:domain *:* 1238/dnsmasq udp 0 0 gondolin:ntp *:* 28138/ntpd udp 0 0 localhost:ntp *:* 28138/ntpd udp 0 0 *:ntp *:* 28138/ntpd udp 0 0 *:49427 *:* 919/avahi-daemon: r udp 0 0 *:ipp *:* 17819/cups-browsed udp6 0 0 [::]:mdns [::]:* 919/avahi-daemon: r udp6 0 0 [::]:56356 [::]:* 919/avahi-daemon: r udp6 0 0 fe80::cc63:b04:481e:ntp [::]:* 28138/ntpd udp6 0 0 ip6-localhost:ntp [::]:* 28138/ntpd udp6 0 0 [::]:ntp [::]:* 28138/ntpd ~ # lsof -i | grep 9091 firefox 3842 russ 79u IPv4 103681669 0t0 TCP localhost:57558->localhost:9091 (ESTABLISHED) firefox 3842 russ 81u IPv4 103686787 0t0 TCP localhost:57562->localhost:9091 (ESTABLISHED) firefox 3842 russ 86u IPv4 103686788 0t0 TCP localhost:57564->localhost:9091 (ESTABLISHED) firefox 3842 russ 90u IPv4 103686789 0t0 TCP localhost:57566->localhost:9091 (ESTABLISHED) java 27508 russ 1699u IPv4 103667313 0t0 TCP *:9091 (LISTEN) java 27508 russ 1730u IPv4 103687885 0t0 TCP localhost:9091->localhost:57562 (ESTABLISHED) java 27508 russ 1731u IPv4 103687886 0t0 TCP localhost:9091->localhost:57564 (ESTABLISHED) java 27508 russ 1732u IPv4 103680156 0t0 TCP localhost:9091->localhost:57558 (ESTABLISHED) java 27508 russ 1734u IPv4 103687887 0t0 TCP localhost:9091->localhost:57566 (ESTABLISHED)
Just a note from Expression Language Guide that if attempting to evaluate an attribute, via evaluateAttributeExpression(), NiFi looks first for a flowfile attribute by that name, then, if missing, for a system environment variable, and that failing, for a JVM system property.
Working on a huge flow, examining performance with JMC/JFR, I have literally hundreds of millions of files that stack up at different queue points, but especially at the end. Ridding myself of all theses files from the queues take something like forever. I posted to ask if anyone had a quick way, but there is none. I tried a) creating a no-op processor drain, but that doesn't go much if at all faster than b) right-clicking the queue and choosing Empty queue.
I even tried a brute-force approach using a script I wrote sitting in my NiFi root:
#!/bin/sh
read -p "Smoke NiFi repositories (y/n)? " yesno
case "$yesno" in
y|Y)
( cd flowfile_repository ; rm -rf * )
( cd provenance_repository ; rm -rf * )
( cd content_repository ; rm -rf * )
;;
*)
;;
esac
...because removing everything from the content repository takes forever—hours for a couple of hundred million flowfiles.
This was predictable, but I wasn't even thinking about it before the accumulation became a problem. After letting the files delete over night, I came in a added a counting processor so I could just let them drain out as they arrived (instead of accumulating them in a queue for counting).
Note too that if the total number of flowfiles in any one connection exceeds the value nifi.queue.swap.threshold in nifi.properties, usually 20,000, swapping will occur and performance can be affected. So, by allowing files to accumulate, I was shooting myself in the foot because I was altering the very performance I was trying to monitor/get a feel for.
I'd never done this before.
How to make "kinkies" in a relationship/connection? Just double-click the line and it will put a yellow handle in it that you can drag to get the connection around any obstruction to make the connection clearer. To remove one that's not/no longer needed, simply double-click the yellow handle. See Bending connections to add a bend or elbow-point.
Someone in the forum wanted a flowfile counter processor. I'll put it here, but just in case, I'll say "no guarantees" too. NiFi's counter cookie jar consists of the lines highlighted below.
package com.etretatlogiciels.nifi.processor;
import org.junit.Test;
import static org.junit.Assert.assertEquals;
import org.apache.nifi.reporting.InitializationException;
import org.apache.nifi.util.TestRunner;
import org.apache.nifi.util.TestRunners;
public class PassThruCounterTest
{
private static final String TEST_VALUE = "test123";
@Test
public void testFlowfileCount() throws InitializationException
{
TestRunner runner = TestRunners.newTestRunner( PassThruCounter.class );
runner.setProperty( PassThruCounter.NAME, TEST_VALUE );
runner.setProperty( PassThruCounter.TYPE, "count" );
runner.enqueue( TEST_VALUE );
runner.run();
final Long actual = runner.getCounterValue( TEST_VALUE );
final Long expected = Long.valueOf( "1" );
assertEquals( actual, expected );
}
@Test
public void testFlowfileSize() throws InitializationException
{
TestRunner runner = TestRunners.newTestRunner( PassThruCounter.class );
runner.setProperty( PassThruCounter.NAME, TEST_VALUE );
runner.setProperty( PassThruCounter.TYPE, "size" );
String value = TEST_VALUE;
runner.enqueue( value );
runner.run();
final Long actual = runner.getCounterValue( TEST_VALUE );
final Long expected = ( long ) value.length();
assertEquals( actual, expected );
}
}
package com.etretatlogiciels.nifi.processor;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.apache.nifi.annotation.behavior.SideEffectFree;
import org.apache.nifi.annotation.behavior.SupportsBatching;
import org.apache.nifi.annotation.documentation.CapabilityDescription;
import org.apache.nifi.components.PropertyDescriptor;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.processor.AbstractProcessor;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.ProcessorInitializationContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.exception.ProcessException;
import org.apache.nifi.processor.util.StandardValidators;
@SideEffectFree
@SupportsBatching
@Tags( { "debugging" } )
@CapabilityDescription( "Counts flowfiles passing or their cumulative sizes." )
public class PassThruCounter extends AbstractProcessor
{
@Override public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.get();
if( flowfile == null )
{
context.yield();
return;
}
final String type = context.getProperty( TYPE ).getValue();
final String name = context.getProperty( NAME ).getValue();
switch( type )
{
case "count" :
session.adjustCounter( name, 1, true );
break;
case "size" :
session.adjustCounter( name, flowfile.getSize(), true );
break;
}
session.transfer( flowfile, SUCCESS );
}
//<editor-fold desc="Properties and relationships">
@Override
public void init( final ProcessorInitializationContext context )
{
List< PropertyDescriptor > properties = new ArrayList<>();
properties.add( TYPE );
properties.add( NAME );
this.properties = Collections.unmodifiableList( properties );
Set< Relationship > relationships = new HashSet<>();
relationships.add( SUCCESS );
this.relationships = Collections.unmodifiableSet( relationships );
}
private List< PropertyDescriptor > properties;
private Set< Relationship > relationships;
public static final PropertyDescriptor TYPE = new PropertyDescriptor.Builder()
.name( "Type" )
.description( "Counter type, one of \"count\" or \"size\" of flowfiles." )
.required( true )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.defaultValue( "count" )
.build();
public static final PropertyDescriptor NAME = new PropertyDescriptor.Builder()
.name( "Name" )
.description( "Name of registered counter." )
.required( true )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.build();
public static final Relationship SUCCESS = new Relationship.Builder()
.name( "success" )
.description( "Continue on to next processor" )
.build();
@Override public List< PropertyDescriptor > getSupportedPropertyDescriptors() { return properties; }
@Override public Set< Relationship > getRelationships() { return relationships; }
//</editor-fold>
}
Some notes on tuning NiFi for high-performance.
A good link for NiFi installation best practice: HDF/NIFI Best practices for setting up a high performance NiFi installation.
I still haven't had time to set up a NiFi cluster which I want to do experimentally (before I ever have to do it because forced).
I came across a random, passing observation that Zookeeper, which is integral to erecting a NiFi cluster, generally recommends an odd number of nodes. I'm sure that, just as for MongoDB, this is about elections.
The perils of moving a processor between packages.
When you change the class (or package) name of a processor, you have effectively removed the processor from your build and added a new one. At that point, NiFi will create a "ghost" processor (in conf/flow.xml.gz) to take its place because the processor class no longer exists.
However, the properties are still retained, in case the processor is added back (reappears). But since NiFi cannot find it, it doesn't know whether the properties are sensitive or not. As a result, it marks all properties as sensitive because it was determined that it is better to share too little information than to share too much.
It's possible to edit conf/flow.xml.gz by hand, if care is taken, I think.
If disk space is exhausted, how to recover unprocessed data since NiFi cannot proceed?
Archived content can be deleted from content_repository:
# find content_repository/ -type f -amin +600 | grep archive | xargs rm -f
(The -amin +600 option means file was accessed 600 or more minutes ago.)
This deletes anything from that archive that is more than 10 hours old. Once this has happened, assuming enough diskspace has been freed up, NiFi can be restarted.
Of course, what partition both the content- and flowfile repositories are on is a consideration. If not the same one, then freeing up old content won't do the trick.
Note that it's theoretically safe to perform these deletions with NiFi running, but there are no guarantees. It's better to halt NiFi first, then restart it.
I need to review some NiFi advice to see where we are on implementing NiFi the correct way. Here are some elements:
The location of these repositories is managed by changing these defaults in conf/nifi.properties:
nifi.content.repository.directory.default=./content_repository nifi.flowfile.repository.directory.default=./flowfile_repository nifi.provenance.repository.directory.default=./provenance_repository
...in conf/nifi.properties, here are the settings discussed above and their defaults:
nifi.provenance.repository.buffer.size=100000 nifi.provenance.repository.max.storage.time=24 hours nifi.provenance.repository.max.storage.size=1 GB nifi.provenance.repository.rollover.time=30 secs nifi.provenance.repository.rollover.size=100 MB nifi.provenance.repository.index.shard.size=500 MB
# JVM memory settings
java.arg.2=-Xms512m
java.arg.3=-Xmx12288m
import org.apache.commons.io.IOUtils;
.
.
.
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.get();
final AtomicReference< String > contents = new AtomicReference<>();
session.read( flowfile, new InputStreamCallback()
{
@Override
public void process( InputStream in ) throws IOException
{
StringWriter writer = new StringWriter();
IOUtils.copy( in, writer );
contents.set( writer.toString() );
}
});
// now the entire flowfile contents are sitting in memory...
}
Note that this setting may be confusing. Let me attempt to explain:
The lower the latency, the more cycles are given to other processors because the batch size is kept smaller. The higher the throughput (which is throughput per invocation, the more that processor hogs cycles for itself.

Depending on what's going on elsewhere in the flow, a lower latency will mean that the processor will simply run more times to process the same number of flowfiles that would have been processed in one invocation when this setting was done to favor throughput. However, this also means:
The run-duration slider control is included in configuration based on the use of the @SupportsBatching annotation. Once you use this annotation, you don't need to do anything in onTrigger() like:
private static final int MAX_FLOWFILES_IN_BATCH = 50;
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
final List< FlowFile > flowfiles = session.get( MAX_FLOWFILES_IN_BATCH );
for( FlowFile flowfile : flowfiles )
{
...
}
..., but just respond with:
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
final FlowFile flowfile = session.get();
if( flowfile == null )
{
context.yield();
return;
}
The slider (the NiFi framework) does the rest: you won't need to worry about the existence of a batch. It just is.
Now, on the other hand, if you need to manage a pool of expensive resources, expensive to allocate, for example, you'd want also to add:
@OnScheduled
public void allocateMyResources( final ProcessContext context ) throws ProcessException
{
try
{
// make a connection, allocate a pool, etc.
}
catch( Exception e )
{
throw new ProcessException( "Couldn't allocate my resources: ", e );
}
}
When you get the error that a flowfile is not the most recent version, it means that you have modified the flowfile in some way via ProcessSession and then attempted to use the flowfile in a variable that preceeds the change. Commonly this happens when you have code that looks something like this:
FlowFile flowfile = session.get(); if( flowfile == null ) return; session.putAttribute( flowfile, "hello", "hello" ); session.transfer( flowfile, SUCCESS );
The issue here is that the ProcessSession.putAttribute() method called above returns a new FlowFile object, and we then pass the old version of the flowfile to session.transfer(). This code would need to be updated to look like this:
FlowFile flowfile = session.get(); if( flowfile == null ) return; flowfile = session.putAttribute( flowfile, "hello", "hello" ); session.transfer( flowfile, SUCCESS );
Note the flowfile variable is re-assigned to the new FlowFile object when session.putAttribute() is called so that we pass the most up-to-date version of the flowfile to ProcessSession.transfer.
On sensitive-value properties...
This is a phenomenon common in controller services, i.e.: properties that hold a password or -phrase or other sensitive sequence that must be hidden from subsequent view. You type it in, confirm it, and never see it again. You can only type it in again.
Here's a long comment I got from Andy LoPresto:
Each sensitive property value is encrypted using the specified algorithm noted in conf/nifi.properties. By default, and therefore on any unmodified system, this is PBEWITHMD5AND256BITAES-CBC-OPENSSL, which means that the actual cipher applied is AES with CBC mode of operation using a 256-bit key derived from the provided nifi.sensitive.props.key value (really a password and not a true key) using the OpenSSL EVP_BytesToKey key-derivation function (KDF), a modified version of PKCS #5 v1.5' MD5-based PBKDF1 identical when the combined length of the key and IV is less than or equal to an MD5 digest and non-standard if greater.
A random 16-byte salt is generated during the encrypt process (the salt length is actually set to be the block length of the cipher in question—AES is always 16 bytes, but if you choose to use DES for example, this value would be 8 bytes), and this salt is provided, along with an iteration count (1000 by default) to the KDF. Internally to the application, this process occurs within the Jasypt library (slated for removal in NIFI-3116), but you can see a compatible Java native implementation of this process in the ConfigEncryptionTool.
If the nifi.sensitive.props.key value is empty, a hard-coded password is used. This is why all documentation should recommend setting that value to a unique and strong passphrase prior to deployment.
Once the key is derived, the sensitive value is encrypted and the salt and cipher text are concatenated and then encoded in hexadecimal. This output is wrapped in "enc{" and "}" tokens to denote the value is encrypted, and then stored in flow.xml.gz. As pointed out elsewhere, the sensitive value (in plain-text or encrypted form) is never sent over the ReST API to any client, including the UI. When editing a processor property that is sensitive, the UI displays a static placeholder.
If two values are the same (i.e. the same password in an EncryptContent processor encrypting and an EncryptContent processor decrypting later in the same flow), the two encrypted values will be completely different in the flow.xml.gz even though they were encrypted with the same key. This is because of the random salt value mentioned above.
The encrypt-config.sh script in nifi-toolkit exposes the functionality to "migrate" the flow.xml.gz encrypted values to be encrypted with a new key. For example, if you read the above and feel uncomfortable with your values encrypted with the default hard-coded password rather than a unique passphrase, you can run this tool and provide a new passphrase, and it will update conf/nifi.properties with the new passphrase (and encrypt it if you have encrypted configuration enabled) and decrypt all values in the flow.xml.gz and re-encrypt them with the new key and repopulate them.
A small note on the migration tool—you may notice that after running it, identical values will have identical encrypted values. This design decision was made because the performance tradeoff of not re-performing the KDF with a unique salt and cipher initialization on each value is immense, and the threat model is weak because the key is already present on the same system. This decision was further impacted by the process by which Jasypt derives the keys. After NIFI-3116 is completed, I feel confident we can improve the security of the cipher texts by using unique IVs without incurring the substantial penalty currently levied by the library structure.
Throughout this explanation, you may have had concerns about some of the decisions made (algorithms selected, default values, etc.). There are ongoing efforts to improve these points, as security is an evolving process and attacks and computational processing availability to attackers is always increasing. More of this is available in relevant JIRAs and the Security Features Roadmap on the wiki, but in general I am looking to harden the system by restricting the algorithms used by default and available in general and increasing the cost of all key derivations (both in time and memory hardness via PBKDF2, bcrypt, and scrypt). Obviously the obstacles in this effort are backwards compatibility and legacy support. It is a balance, but with the support of the community, I see us continuing to move forward with regards to security while making the user experience even easier.

This morning, NiFi queue prioritization...
To impose prioritization on flowfiles, you configure a (stopped) queue, by right-clicking it and choosing Configure. Look for the Settings tab. Then grab one of:
This morning's note is about PriorityAttributePrioritizer.
The PriorityAttributePrioritizer prioritizes flowfiles by looking for a attribute named priority, then sorting the flowfiles using the lexicographical value of the priority marked therein.
Brian Bende pointed out that, coming out of various feeds (let's say some processor groups), you can set the priority attribute using UpdateAttribute to weight the various feeds according to a sense of priority. Before continuing the flow, you can converge all the flows into one using a funnel.
The provenance repository writes out the data "inline" as flowfiles traverse the system. It rolls over periodically (by default every 30 seconds or after writing 100 MB of provenance data). When it rolls over, it begins writing data to a new (repository) file and starts to index the events for the old file in Lucene. The events are not available in the UI until they have been indexed into Lucene. This could be a few minutes depending on the system and how many provenance events are being generated, see Persistent Provenance Repository Design.
This said, the existing implementation (1.1.x) is not as fast as it could be. In the next release of NiFi, there is an alternate implementation that can be used. See Provide a newly refactored provenance repository.
If you want to see when/who stopped a processor in NiFi (and other configuration changes) you can use the Flow configuration history (the clock icon on the right side of the menu bar in 0.7.x) and filter by processor id.
Just a note to remember that AbstractProcessor extends AbstractSessionFactoryProcessor and that the real delta between them is the second argument to onTrigger(), where the subclass offers ProcessSession in place of the ProcessSessionFactory. The latter gives the ability to create a new session (with sessionFactory.createSession().
Here are some excellent details on NiFi-processor semantics by Andy LoPresto and Mark Payne. First Andy...
In the Developer Guide, there are discussions of various processor patterns, including Split Content, and a section on Cohesion and Usability, which states:
"In order to avoid these issues, and make processors more reusable, a processor should always stick to the principal of 'do one thing and do it well.' Such a processor should be broken into two separate processors: one to convert the data from format X to format Y, and another processor to send data to the remote resource."
I call this the "Unix model," i.e.: it is better to join several small, specific tools together to accomplish a task than re-invent larger tools every time a small modification is required. In general, that would lead me to develop processors that operate on the smallest unit of data necessary—a single line, element, or record makes sense—unless more context is needed for completeness, or the performance is so grossly different that it is inefficient to operate on such small quantities.
Finally, with regards to your question about which provenance events to use in various scenarios, I agree the documentation is lacking. Luckily Drew Lim did some great work improving this documentation. While it has not been released in an official version, both the Developer Guide and User Guide have received substantial enhancements, describing the complete list of provenance event types and their usage or meaning. This work is available on master and will be released in 1.2.0.
Different processors have different philosophies. Sometimes that is the result of different authors, sometimes it is a legitimate result of the wide variety of scenarios that these processors interact with. Improving the user experience and documentation is always important, and getting started with and maximizing the usefulness of these processors is one of several top priorities.
Next, Mark...
On Provenance Events, while the documentation does appear to be lacking there at the moment, the framework does its best to help here. Here is some additional guidance:
Regarding processors handling all of the data vs. only a single "piece" of the data:
Processors should handle all of the content of a flowfile, whenever it makes sense to do so. For example, if you have a processor that is designed to operate on the header of a CSV file then it does not make sense to read and process the rest of the data. However, if you have a processor that modifies one of the cells in a row of a CSV file it should certainly operate on all rows. This gives the user the flexibility to send in single-row CSV files if they need to split it for some other reason, or to send in a many-gigabyte CSV file without the need to pay the cost of splitting it up and then re-merging it.
Where you may see the existing processors deviate from this is something like ExtractText, which says that it will only buffer up to the configured amount of data. This is done because in order to run a regular expression over the data, the data has to be buffered in the Java heap. If we don't set limits to this, then a user will inevitably send in a 10Gb CSV file and get "out of memory errors." In this case, we would encourage users to use a small buffer size such as 1Mb and then split the content upstream.
I asked the question,
The ability to create a new session is conferred by extending AbstractSessionFactoryProcessor (in lieu of AbstractProcessorwhich which further restricts Processor, among other things, removing the session factory) giving one the option of calling sessionFactory.createSession(). This begs the question of why or when would I wish to create a new session rather than operate within the one I'm given (by AbstractProcessor)?
Mark Payne and Matt Burgess responded, Mark wrote:
MergeContent is a good example of when this would be done.
It creates a ProcessSession for each "bin" of flowfiles that it holds onto. This allows it to build up several flowfiles in one bin and then process that entire bin, committing the ProcessSession that is associated with it. Doing this does not affect any of the flowfiles in another bin, though, as they belong to a different ProcessSession. If they all belonged to the same ProcessSession, then we would not be able to commit the session whenever one bin is full. Instead, we would have to wait until all bins are full, because in order to commit a ProcessSession, all of its flowfiles must be accounted for (transferred or a relationship or removed).
So in a more general sense, you would want this any time that you have multiple flowfiles where you need them to belong to different session so that you can commit/rollback a session without accounting for all flowfiles that you've seen.
The AbstractSessionFactoryProcessor is also sometimes used when we want to avoid committing the session when returning from onTrigger(). For example, if there is some asynchronous process going on.
Matt:
There are a couple of use cases I can think of where you'd want AbstractSessionFactoryProcessor over AbstractProcessor:
@SupportsBatching leads to that "slider" seen in a processor's configuration. It's a hint only, but has no material effect upon how to code the processor (in terms of special things to do).
A greater than 0 delay (see the slider) will cause the flowfiles over that time period to be batched out such that the work will be done, but no commit until the end of the delay (in slider).
At least by NiFi 1.1.1, the following became a possibility:
In ${NIFI_ROOT}/conf/nifi.properties, add this line:
nifi.variable.registry.properties=./conf/registry.properties
You can list more than one file, separated by commas. Then, create this file (registry.properties) locally with contents:
zzyzzx="This is a test of the Emergency Broadcast System. This is only a test."
Next, create a flow using CreateFlowFile (and start it) connected to UpdateAttributes, which you configure thus:
Property Value
ZZYZZX ${zzyzzx}
...(starting this processor too) then on to NoOperation (that you don't start) so there's a flowfile in the queue you can look at. Bounce NiFi because these properties are static. Once there's a flowfile in the queue in front of NoOperation, right-click and choose List Queue, then click the View Details and, finally, the Attributes tab. You'll see attribute ZZYZZX with the property value assigned by registry.properties in our example.
Only the flowfile_repository need be removed (as long as data is not important): removing that repository means that the contents of the content_repository will be removed by NiFi since no flowfiles point to its contents anymore.
It's possible also/instead of to set nifi.flowcontroller.autoResumeState in conf/nifi.properties to false, then piecewise alleviate large queues or processing of files that could be causing the failure to restart.
You create a new processor, everything's perfect, then you move it out of your larger project to its own home ('cause that's needful), but then you cannot load it. The NAR builds, NiFi's happy to load it, but when you go to do Add Processor in the UI, it's not there. You pull your hair out, you cry on the shoulder of sympathetic souls in the community forum, then someone points out that you spelled META-INF with an underscore instead of a hyphen.
What's left to do, but look for a sword to fall on?
Here's a list of things to check that I will add to as more ideas occur to me.
Bryan Bende makes some useful points in a post. I am going to be dealing with moving our authentication strategy from 0.7.1 over to 1.1.2 very soon, so I'm copying this post here for safe-keeping and quick access.
So to add a new node, you would run the tls command again with the new hostname, but it has to be done from the same location where you ran it before because you want it to use the existing nifi-cert.pem and nifi-cert.key, so that the certificate of the new node is signed by the same CA as the other nodes.
$ ./bin/tls-toolkit.sh standalone -n new-hostname
You won't have to update anything on the existing nodes because they already trust the CA.
As far as users of the web UI... If there are different LDAPs then these are just two different accounts and the user has one account to log in with at site 1 and another account to log in with at site 2. If you want all users to be the same across site 1 and site 2 then they should be pointing at the same central LDAP.
https://nifi.apache.org/docs/nifi-docs/html/administration-guide.html#multi-tenant-authorization
I found an interesting comment I want to keep written by Andy LoPresto to someone today about MiniFi.
NiFi can run on small hardware, such as a Raspberry Pi. You may also be interested in MiNiFi a sub-project of NiFi. MiNiFi is a "headless agent" tool which is designed to run on lightweight or shared systems and extend the reach and capabilities of NiFi to the "edge" of data collection. MiNiFi offers two versions—a Java version which has a high degree of compatibility with NiFi (many of the native processors are available), and a C++ version which is extremely compact but has limited processor definition at this time. MiNiFi may also be a better fit for a "non-UI workflow," as the flow can be defined using the GUI of NiFi and then exported as YAML to the MiNiFi agent, or written directly as YAML if desired.
It looks like using NiFi 1.1.2 incurs a problem until 1.2.0 in that Jetty uses /dev/random. This generator will, the first time used on a machine, spend up to 10 minutes accumulating data from noise in order to be completely random. This would be the case every time in a launch of a virtual machine (since every launch is brand new "hardware"), so a JVM option can be used to change this. To override the use of /dev/random, set java.security.egd to use /dev/urandom. However, at least in the Oracle JVM, that string is noted and reinterpreted to be /dev/random thus thwarting the override. Instead use this incantation to get around it:
java.args.N=-Djava.security.egd=file:/dev/./urandom
...in ${NIFI_ROOT}/conf/bootstrap.conf.
See How to solve performance problem with Java SecureRandom? and First deployment of NiFi can hang on VMs without sufficient entropy if using /dev/random. .
Some notes on latency and through-put...
Some processors have, under the Scheduling tab of the Configure Processor dialog, a slider, Run Duration, that permits a balance to be set between latency and through-put.
This slider appears on processors making use of the @SupportsBatching annotation.
The way to think about it is to see the slider as representing how long a processor will be able to use a thread to work on flowfiles (from its in-bound queue), that is, allowing onTrigger() to run more times to generate more out-bound flowfiles. Moving the slider further to the right makes the processor do more work, but at the same time, the processor will hog the thread for a longer period of time before it gives it up to another processor. Overall latency could go down because flowfiles will sit in other queues for longer periods of time before being serviced by their processor (that is, the processor waiting to serve the queue they're sitting in) because other processors don't get the thread that the first one is hogging.
For processors that are willing to delegate the responsibility of when to commit what they've finished to the framework, in a transactional sense, the framework can then use that understanding to combine one or more into a single transaction. This trades off some small latency for what is arguably higher throughput because the framework can do a single write to the flowfile repository in place of doing many writes reducing thus the burden on various locks, filesystem interrupts, etc. In some cases, this is more friendly and has the effect of higher through-put.
If a flow has and handles flows from numerous, perhaps competing concerns, teams, organizations, etc., this must be tunable.
Whether or not to annotate with @SupportsBatching, enabling the existence of this slider, it comes down to whether the processor can or is willing to let the framework control when to commit the session's work. This would be the case when work isn't side-effect free (cf. @NoSideEffects) in which something, some state, has been altered in ways from which actions taken could not be recovered from. For example, PutSFTP will send data via SFTP. Once a file is sent, it cannot be "unsent" and the process cannot be repeated without side effect. This processor would not be a candidate for allowing the framework to decide.
I had the opportunity of witnessing what happens when a NAR is inadvertantly restructured resulting in processors ending up on different package paths to where they were before. Of course, they no longer work as they are no longer there in support of processors in existing flows. NiFi makes "ghosts" when that happens and, of course, those ghosts don't work. I was impressed, however, by what happened. I half-expected some cataclysm with damage to flow.xml.gz. The only thing that happened was an exception in logs/nifi-app.log, a comment about the ghost created, then in the flow, the processors weren't operable, but they were still there and still connected.
When I corrected the situation, everything worked again.
Today I'm going to corral the topic of responding to changes in configuration. Typically, a processor's properties will remain fixed once established, but it doesn't have to be that way. I'm especially interested in optimizing gathering properties since some properties might be expensive to gather if they need further treatment after gathering.
It's desirable, therefore, for a processor to react when its properties have changed. The method, onPropertyModified(), is inherited from AbstractProcessor and is called when these have changed, once for each modified property:
/**
* Called only when a NiFi user actually updates (changes) this property's value.
* @param descriptor the property.
* @param oldValue null if property had no previous value.
* @param newValue null if property has been removed.
*/
@Override
public void onPropertyModified( final PropertyDescriptor descriptor, final String oldValue,
final String newValue )
This brings up also NiFi's component lifecycle, which is governed by means of annotations. Methods are annotated to be called when the lifecycle event occurs.
So, what does this mean for property management?
It means you define static properties (and relationships) in your init() method. However, dynamic properties are not there at the time init() is called since they're dynamic and you can't predict them.
If you expect multiple instances of your processor (duh), you'll want to use instance variables to hang on to your properties. You'll also want instance variables, in the case of expensive, derivative work fo the sort that prompted me to think about this today in the first place (because I've not previously had this challenge of expensive operations as a result of property values that could change), so that each instance of your processor has and deals with this expense separately. (Of course, you shouldn't use static variables for stuff like this.)
The most efficient way to react only to expensive decisions is to watch @OnScheduled. That's the time that your processor is about to run, you want to lock down all the meaningful data then rather than keep doing it over and over again each time onTrigger() is called.
If you've got any deconstruction concerns, which would be rare, you'd want to handle those in an @OnStopped setting. Don't do this in an @OnUnscheduled method because the processor threads aren't halted by then and you'd be pulling the rug from under their feet.
Last, if you want precision reaction only to those properties reported as modified, you can finesse it by writing a method I evoked at the beginning, onPropertyModified().
For the present work, some of this has proven useful and I'm content.
Important note in @OnSceduled methods: It's important here that unvalidated properties, in this case only the rules from dynamic properties, don't lead (when missing or bad) to a situation that result in exceptions, errors, etc. that aren't carefully handled (by clear warning). Otherwise, no sooner is the processor started up on the UI canvas than it gets a potentially confusing error/warning notation on it.
...from comments by Mark Payne.
NiFi relies upon Apache Zookeeper to coordinate which node acts as coordinator and which as primary. An embedded Zookeeper is an option, but for production use, an external one running on different hosts is recommended.
For getting started, the nifi.cluster.node.connection.timeout and the nifi.cluster.node.read.timeout properties are set to 5 seconds by default, but garbage collection for large numbers of flowfiles could cause pauses longer than that, so it's recommended to increase these values to 10 or even 15 seconds. Similarly, change nifi.zookeeper.connect.timeout and nifi.zookeeper.session.timeout to 5 or 10 seconds.
And, something else important (if also a bit "duh?!") I discovered. Unless something is specifically done to make nodes in a NiFi cluster exchange data in a flow (and this isn't for the faint-hearted), a flowfile will always remain on the same node that created it, beginning to end.
Later note: prior to NiFi 1.8, it was necessary to use a remote-process group connected to the cluster via an input/output port plus the site-to-site protocol to load-balance data running through a NiFi cluster. Beginning with 1.8, however, it became possible to configure this in the relationship between any two processors.
Counter-intuitively, here's how to export, then import a template. I say this because I don't find this interface all that compelling and could come up with a more logical one myself. Nevertheless, we're certain happy that this is possible at all.
The first sequence is exporting the template while browsing one NiFi flow. The second sequence shows importing the template while browsing another (or the same) NiFi flow. Finally, the last sequence shows incorporating the contents of the template as a new NiFi flow.


Yesterday, I learned (or reinforced having learned it before) that our searchadmin user cannot touch the NiFi canvas/flows—only examine it (them). This is because, sometime in the history of NiFi 1.x, it became the case that a user is created and able to create other users then endow them with the ability to do this, but not do it (not by default, that is) by itself.
The symptom of this was, because I was logged in from a user with rights to assign rights, but without rights to edit the flow, much of the UI was greyed out.
So, one thing I had to do yesterday was to create a new user, russ, on the test server (above) that can create, modify and delete NiFi flows. Here are some notes on this using a new user, jack. A new user is created in LDAP whence it's consumed by NiFi. Then, manage NiFi this way:
Access Denied Unable to perform the desired action due to insufficient permissions. Contact the system administrator.you've neglected something. You'll need to log out, log back in as searchadmin, and fix it. Likely, the user doesn't have adequate privileges to view the user interface. It's always better to manage the policies via General → Policies than via the Operate → Access Policies method. For some reason, you don't see all the policies via the second method which is the one I suggested in these steps. Sorry.
Note that, while this is overly complicated and nasty, there is a way to work around it. To do this, create a new group that can read and write the UI canvas, then just add users into that group. Note that it need not be an LDAP group, only a group for convenience in NiFi.
The behavior of creating a property as a dynamic one (e.g.: creating using the builder with method .isDynamic( true ) ) does lead to a nice, dynamic-looking property in the configuration dialog replete with a trashcan icon/control, but deleting the property doesn't in fact delete it: the next time you open the configuration dialog, it's back and, anyway, it remains in the list of properties to consider when you iterate through them, i.e.:
for( Map.Entry< PropertyDescriptor, String > property : context.getProperties().entrySet() )
{
PropertyDescriptor descriptor = property.getKey();
if( descriptor.isDynamic() )
...
}
Separately, in JUnit testing a processor, you add dynamic properties in the same way as static ones for the purpose of testing, so this doesn't inform you much in the behavior noted in my first paragraph.
Joe Witt said that the dynamic-property mechanism wasn't really set up to work for what I want to do (preconfigure some very likely defaults to speed up what my users have to do). The answer is to pre-add properties with a boolean enabling property and let them turn them off instead. In my precise need, this works fine though I'm pretty sure the idea has some merit.
My IT guy is interested in back-ups of NiFi, so I thought I'd do a little research on it. Here are some notes of my own and some taken from the research I'm doing this morning. I haven't been overly interested in this aspect of NiFi in the year-plus I've been writing processors to solve problems using this framework.
It's important to note that restoring the running state of an instance including being able to reproduce the instance since restarting NiFI with content (live data) that doesn't match the flow definition is icky at best. The most encouraging thing that can be said is that doing this puts NiFi in an undefined state and you can expect undefined results from it.
On a NiFi cluster, there are additional configuration files that would need to be backed up, in particular, those associated with Zookeeper, conf/zookeeper.properties.
Since NiFi 1.0, templates have begun to be collected in this file. Previously, they were kept in conf/templates.
Mark Payne offered this advice:
Given that the content and flowfile repositories are intended to be rather short-lived, I'm not sure that you'd really have need to backup the repository (if you were to pause the flow in order to back it up, for instance, you could likely process the data just as fast as you could back it up—and at that point you'd be finished with it). That being said, for a production-use case, I would certainly recommend running on a RAID configuration that provides redundancy so that if a disk were to go bad you'd still be able to access the data.
For the provenance repository, there actually exists a reporting task that can send the data via site-to-site so that it can be exfilled however you see fit in your flow.
As long as the content of a flowfile doesn't change, but only attributes, only a reference is maintained to it—not separate copies.
To turn on logging to get help with a standard NiFi processor, let's pick InvokeHTTP, paste this line into (toward the bottom) ${NIFI_ROOT}/conf/logback.xml:
<logger name="org.apache.nifi.processors.standard.InvokeHTTP" level="DEBUG"/>
If your unit test needs to check for cross-contamination by simulating two, consecutive runs of your processor, you instantiate a new TestRunner only once, for sure, but after checking out the results from the first call to runner.run( 1 ), you need to call runner.clearTransferState() to put the "processor instance" back in the state it would be (fresh) for the next call.
I found by accident and more specifically what's troubling me in my case.
Of course, the real problem is having older slf4j JARs linked into your binary because of ancient code. That's the real problem and the rest of this thread was taken up with getting to the real problem. However, ...
...now I know why not all of my test code encounters this problem. It's because it only happens when I use NiFi ComponentLog (or the test framework uses it). As long as execution never wanders down into that, I don't have the problem. It's the call to getLogger().{info|warn|etc.} that does it.
So, if you don't make any mistakes in your test code calling into the NiFi test framework, you're a lot less likely to encounter this. You also must not put a call to getLogger().{info|warn|etc.} into your custom-processor code.
Now, oddly, that NiFi call or my custom processor call getLogger().info(), etc. does not exhibit this problem in production, only when JUnit tests are running.
Makes an old C hack like me wish for a preprocessor. I wrote a class, NiFiLogger, to work through and that I disable in favor of System.out.println() when running tests. Down the road I'll be able to take that out.
You have a processor that appears to be stopped, but also claims to be running two threads.
This is a stuck thread and there's no way, using the UI, to unstick the threads. You can bounce NiFi.
First, however, you can do
$ bin/nifi.sh dump
...to cause NiFi to do a dump to logs/nifi-bootstrap.log to find out why the threads are stuck.
There's a simple, key-value pair store available for processors, controller services and reporting context, that allows for cluster-wide or local storage of state.
For example, if you want to remember what the last record you got doing some query, and you're the author of the processor doing it, you can add state to do that. The API consists of:
(The implications of cluster state differ considerably from local state, so read up on this.)
Two processors cannot share state; it's per-processor only. To share state between processors, resort to a controller service for this, that is, to bind two processors to the same controller service and that service exposes thus its (otherwise) private state effectively shared between the two consuming processors.
There is unit-test framework support for this. See notes on this date for working example.
It turns out that General → Controller Settings... produces nothing useful. This is because, unless you configure a controller service from Operate → (gear icon) or from a processor's configuration directly, you haven't got useful configuration. This is because controller service configuration is now process group-specific:
Understanding Controller Service Availability in Apache NiFi, paragraph 2. This represents a pretty big change since NiFi 0.x.
Incidentally, I think it's super important, when configuring controller services, to give them a name beyond their coded name—a name that describes what they're supposed to do for any configuration processor. That way, you don't have to sort through myriad instances of the same controller looking for the one you want.
I worked on the "NiFi rocks!" example of a controller service to excerpt (or "highlight") more or less the crucial bits because I wrote a controller service this week, had some trouble getting it to work just right (especially creating unit tests for it).
Here is the interface. Oddly, this is the very thing by which the controller service is always referenced (instead of StandardPropertiesFileService). In short, this interface must be able to say it all. Anything it doesn't say won't be easily accessible. Here, it says that the implementing controller service must make a method, String getProperty( String key ) available. Anything else the service does is immaterial: this method is the sole article in the contract. I have highlighted lines that are crucial to stuff in order to work.
package com.etretatlogiciels.nifi.controller.interfaces;
import org.apache.nifi.controller.ControllerService;
public interface PropertiesFileService extends ControllerService
{
String getProperty( String key );
}
The controller service that extends PropertiesFileService just does that, implements what it does completely behind the contractual String getProperty( String key). Sure, onConfigured() does all the heavy lifting when called, but just sets up what String getProperty( String key ) will return when called by the consuming NiFi processor configured to use the controller service.
package com.etretatlogiciels.nifi.controller;
import com.etretatlogiciels.nifi.controller.interfaces.PropertiesFileService;
@CapabilityDescription( "Provides a controller service to manage property files." )
public class StandardPropertiesFileService extends AbstractControllerService implements PropertiesFileService
{
private String configUri;
private Properties properties = new Properties();
@OnEnabled
public void onConfigured( final ConfigurationContext context ) throws InitializationException
{
configUri = context.getProperty( CONFIG_URI ).getValue();
...
}
@Override public String getProperty( String key ) { return properties.getProperty( key ); }
public static final PropertyDescriptor CONFIG_URI = new PropertyDescriptor.Builder()
.name( "Configuration Directory" )
.description( "Configuration directory for properties files." )
.defaultValue( null )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.build();
}
This is the consuming processor. Note that it never references the controller service directly when it identifies the service nor when it gets the product of the service, but always and only the interface upon which the controller service is built:
package com.etretatlogiciels.nifi.processor;
import com.etretatlogiciels.nifi.controller.interfaces.PropertiesFileService;
@CapabilityDescription( "Fetch value from properties service." )
public class Processor extends AbstractProcessor
{
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
final String propertyName = context.getProperty( PROPERTY_NAME ).getValue();
final PropertiesFileService propertiesService = context.getProperty( PROPERTIES_SERVICE )
.asControllerService( PropertiesFileService.class );
final String property = propertiesService.getProperty( propertyName );
...
session.transfer( flowfile, SUCCESS );
}
public static final PropertyDescriptor PROPERTY_NAME = new PropertyDescriptor.Builder()
.name( "Property Name" )
.required( true )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
.build();
public static final PropertyDescriptor PROPERTIES_SERVICE = new PropertyDescriptor.Builder()
.name( "Properties Service" )
.description( "System properties loader" )
.required( false )
.identifiesControllerService( PropertiesFileService.class )
.build();
...
}
Last, but far from least, the JUnit test...
Another challenge, equally difficult to coding a controller service is writing a test for one. The highlighted lines are those germane to testing the controller service and not other testing issues.
Notice that, while a new instance of the controller service itself, StandardPropertiesFileService, is created, it's again the interface that's referenced and not the service class itself (line 13). So, when it's time to add the controller service to the test framework (runner) and to enable it, it's the interface reference that's used (line 26).
Note how the controller-service property is loaded ahead of time into a private hash map (line 16) referencing the static PropertyDescriptor in the service (there is no PropertyDescriptor in the interface) directly prior to the association of the properties map with the interface reference when the service is added to the test framework (line 26 as already noted).
Let's detail the three lines (26-28) that are of crucial importance. If you don't get these right, there are some rather cryptic errors that come out of the test framework.
The other properties shown explicitly set up in the framework (one, actually, on line 31), using setProperty(), are those of the processor being tested (and not of the controller service).
package com.etretatlogiciels.nifi.processor;
import com.etretatlogiciels.nifi.controller.StandardPropertiesFileService;
import com.etretatlogiciels.nifi.controller.interfaces.PropertiesFileService;
public class ProcessorTest
{
@Test
public void testOnTrigger() throws IOException, InitializationException
{
TestRunner runner = TestRunners.newTestRunner( new Processor() );
PropertiesFileService propertiesService = new StandardPropertiesFileService();
Map< String, String > propertiesServiceProperties = new HashMap<>();
propertiesServiceProperties.put( StandardPropertiesFileService.RELOAD_INTERVAL.getName(), "30 sec" );
URL url = this.getClass().getClassLoader().getResource( "test.properties" );
assertNotNull( "Should not be null", url );
String propFile = url.getFile();
propertiesServiceProperties.put( StandardPropertiesFileService.CONFIG_URI.getName(), propFile );
// Add controller service
runner.addControllerService( "propertiesServiceTest", propertiesService, propertiesServiceProperties );
runner.enableControllerService( propertiesService );
runner.setProperty( Processor.PROPERTIES_SERVICE, "propertiesServiceTest" );
// Add properties
runner.setProperty( Processor.PROPERTY_NAME, "hello" );
// Add the content to the runner
runner.enqueue( "TEST".getBytes() );
// Run the enqueued content, it also takes an int = number of contents queued
runner.run( 1 );
// All results were processed with out failure
runner.assertQueueEmpty();
// If you need to read or do additional tests on results you can access the content
List< MockFlowFile > results = runner.getFlowFilesForRelationship( Processor.SUCCESS );
assertTrue( "1 match", results.size() == 1 );
MockFlowFile result = results.get( 0 );
// Test attributes and content
result.assertAttributeEquals( "property", "nifi.rocks.prop" );
}
}
ExecuteScript to run a Python script that runs on a single flowfile despite having multiple flowfiles in the queue is very inefficient. The slowness is due to the Jython initialization time.
At the top of your Python script, put:
flowFiles = session.get( 10 )
for flowFile in flowFiles:
if flowFile is None:
continue
# do stuff here...
Here are two sample scripts.
flowfiles = session.get( 10 )
for flowfile in flowfiles:
if flowfile is None:
continue
s3_bucket = flowfile.getAttribute( 'job.s3_bucket' )
s3_path = flowfile.getAttribute( 'job.s3_path' )
# More stuff here....
errors = []
# More stuff here...
if len( errors ) > 0:
flowfile = session.putAttribute( flowfile, 'job.error', ';'.join( errors ) )
session.transfer( flowfile, REL_FAILURE )
else:
flowfile = session.putAttribute( flowfile, 'job.number_csv_files', str( len( matches ) ) )
flowfile = session.putAttribute( flowfile, 'job.total_file_size', str(total_size ) )
session.transfer( flowfile, REL_SUCCESS
)
import sys
import traceback
from java.nio.charset import StandardCharsets
from org.apache.commons.io import IOUtils
from org.apache.nifi.processor.io import StreamCallback
from org.python.core.util import StringUtil
flowfiles = session.get( 10 )
for flowfile in flowfiles:
if flowfile is None:
continue
start = int( flowfile.getAttribute( 'range.start' ) )
stop = int( flowfile.getAttribute( 'range.stop' ) )
increment = int( flowfile.getAttribute( 'range.increment' ) )
for x in range( start, stop + 1, increment ):
newFlowfile = session.clone( flowfile )
newFlowfile = session.putAttribute( newFlowfile, 'current', str( x ) )
session.transfer( newFlowfile, REL_SUCCESS )
session.remove( flowfile )
When a node joins a cluster it writes its node identifier into its local state. This is in a state directory under the NiFi installation, which is state/local, I think.
If that subdirectory is removed, the node will get a new identifier. If the subdirectory is left in place, the node gets that same identifier when the NiFi node is started again.
You have many files in some subdirectory. Let's say they're named file1.csv, file2.csv, etc. How to ensure they're processed sequentially?
There is a processor, EnforceOrder, available beginning in NiFi 1.2.0. Here's a (nice, if complex) flow that Koji Kawamura offers that solves this (and a number of other problems that might arise):
Note, however, that EnforceOrder suffers from needing the object of its counting mechanism to increment not only in-order, but also without skipping any counting values—not so much as even 1.
Matt Burgess answered a question from me in the forum and gave some useful detail. I was struggling to do some Mockito work on a class instantiated in init().
A processor's init() method should be getting called at creation time, sic:
TestRunner runner = TestRunners( new MyProcessor() );
It calls Processor.initialize() and AbstractSessionFactoryProcessor's implementation calls its own protected init() method (which is usually what MyProcessor overrides). It also calls any methods that were annotated with @OnAdded and @OnConfigurationRestored. These could be split out if necessary, or organized just as TestRunner's methods are. TestRunner has some overloaded methods for run(), the base one is:
public void run( final int iterations, final boolean stopOnFinish, final boolean initialize, final long runWait );
If you call run() with no parameters, you'll get 1 iteration that initializes then stops on finish (with a 5 second run-wait). However specifying initialize as true will only invoke methods bearing an @OnScheduled annotation.
If you keep a reference to your instance of MyProcessor, you can call your @OnScheduled method explicitly (rather than via TestRunner), then perform your assertions, etc. Then if you want to run onTrigger() but you don't want to reinitialize, you can do:
runner.run( 1, true, false )
...which says to run once, stop on finish, and don't initialize.
There are a couple examples of manipulating the run() methods in CaptureChangeMySQLTest.groovy.
Here's how to interact with a flowfile in both input- and output modes:
flowfile = session.write( flowfile, new StreamCallback()
{
@Override
public void process( InputStream in, OutputStream out ) throws IOException
{
try
{
// use InputStream in and OutputStream out at the same time...
}
finally
{
in.close();
out.close();
}
}
});
Steps to keep original flowfile (for passing along) while creating a new flowfile with content too.
session.read( flowfile, new InputStreamCallback()
{
@Override
public void process( InputStream existing ) throws IOException
{
newContentHolder.set( ... );
}
});
flowfile = session.write( flowfile, new OutputStreamCallback()
{
@Override
public void process( OutputStream out ) throws IOException
{
out.write( newContentHolder.getBytes() );
}
});
You get this exception saying that your relationship is not known:
java.lang.IllegalArgumentException: this relationship relationship-name is not known
Did you forget one of these elements in your processor code?
public static final Relationship relationship-name = new Relationship.Builder()
...
.build();
@Override
public void init( final ProcessorInitializationContext context )
{
Set< Relationship > relationships = new HashSet<>();
relationships.add( relationship-name );
this.relationships = Collections.unmodifiableSet( relationships );
}
@Override public Set< Relationship > getRelationships() { return relationships; }
Is there a way to know when a flowfile is looked at by someone in the UI?
We have flowfiles containing personal health data (PHI) which no one is supposed to see, but in the case where it's unavoidably crucial to take a look, for debugging or otherwise observing the functioning of a flow, we must know the extent of exposure for legal reasons.
Joe Witt answered,
"This is precisely why there is a DOWNLOAD event type in provenance. I recommend using that mechanism to track this. You can also register an authorizer which based on tags of the data and which user/entity is trying to access a given resource—whether they are allowed."
I need a very light amount of state management, only one variable. However, the basic functionality is to give you Map< String, String > as a map of all the values you want. To get one value, it's:
private String getValueFromStateManager( final ProcessContext context, final String key )
{
StateMap map = context.getStateManager().getState( Scope.LOCAL );
return( map != null ) ? map.get( key ) : null;
}
and, to manage the value, you have to juggle the entire map. Here, I replace it wholesale since I've only got one value I care about.
private void putLastTransactionNumber( final ProcessContext context, final String key, final String value )
throws IOException
{
Map< String, String > map = new HashMap<>( 1 );
map.put( key, value );
context.getStateManager().setState( map, Scope.LOCAL );
}
This isn't a whole custom processor, just as much code as you'd need to recognize what's going on. The state being saved is nothing more than the index of the last operation undertaken successfully.
It looks complicated, but typically, you would handle all of this in small methods rather than right inside your custom processor's onTrigger() method.
State is specific to an instance of a processor on the flow. Safety ends there. If the processor is allowed to have multiple tasks running concurrently then the state mechanism's usage will have to be protected just as with any other variable in the scope of the processor. If the scope is Scope.LOCAL then this is really all you need to think about. If, however, the scope is Scope.CLUSTER then, generally speaking, the intent of usage for that is often associated with a primary node-only action like a ListX processor (like ListFile) with the idea being that the state can be restored by some other node if it's assigned that role.
It's probably best to use the replace() method in StateManager to perform a compare-and-set which would make sure that what's being sent back is accurate based on the previous state retrieved.
The compare-and-set operation is implemented by the underlying provider, which is the write-ahead log for local, and ZooKeeper for cluster
StateManager provides a set-state method and a replace-state method. The former will update the state to whatever is passed. The latter allows the expected state to be passed such that the value is atomically replaced, similarly to how ConcurrentMap works.
package com.windofkeltia.nifi.processor;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.nifi.components.state.Scope;
import org.apache.nifi.components.state.StateMap;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.exception.ProcessException;
public class ProcessorExample
{
private static final String LAST_MPID_KEY = "LAST_MPID";
private static final String FAILED_LIST_KEY = "FAILED_MPIDS";
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
int mpid;
StateMap stateMap;
Map< String, String > state;
try
{
/* Get state and the map; if the map is empty, this will nevertheless
* create one to put later...
*/
stateMap = context.getStateManager().getState( Scope.LOCAL );
state = new HashMap<>( stateMap.toMap() );
}
catch( IOException e )
{
throw new ProcessException( "Problem get processor state map", e );
}
try
{
mpid = Integer.parseInt( state.get( LAST_MPID_KEY ) );
}
catch( NumberFormatException e )
{
// we're the first? let's start out at mpid == 1...
state.put( LAST_MPID_KEY, 1 + "" );
mpid = 1;
try
{
context.getStateManager().setState( state, Scope.LOCAL );
}
catch( IOException failedStateManager )
{
throw new ProcessException( "Failed to establish/update processor state map", failedStateManager );
}
}
try
{
state.put( LAST_MPID_KEY, "" + mpid+1 );
context.getStateManager().setState( state, Scope.LOCAL );
}
catch( IOException e )
{
throw new ProcessException( "Unable to update processor state map", e );
}
// do something with mpid...
boolean successful = foo( mpid );
if( successful )
{
/* Update state. NiFi's StateManager handles concurrent access to state.
*/
try
{
context.getStateManager().setState( state, Scope.LOCAL );
}
catch( IOException e )
{
throw new ProcessException( "Failed to establish/update processor state map", e );
}
}
else
{
/* We failed for this mpid. Make a note of that.
*/
try
{
String list = state.get( FAILED_LIST_KEY );
list += "," + mpid;
state.put( FAILED_LIST_KEY, list );
context.getStateManager().setState( state, Scope.LOCAL );
}
catch( IOException e )
{
throw new ProcessException( "Failed to note our mpid's failure in the processor state map", e );
}
}
}
private boolean foo( int mpid )
{
System.out.println( "mpid = " + mpid );
return true;
}
}
It seems useful to note, so it turns up in a search, how/why a transfer Relationship might not be specified. I've got to where this isn't hard for me to find, but it's something to note nevertheless for posterity.
Quite often, when a "transfer relationship not specified" error occurs, it's the result of a bug in error handling. For example, the flowfile is to be routed to failure for some reason, but the part of the code that does that has itself a problem and fails.
Remote-process groups (RPG) handle balancing and failover for you. This is a comment by Bryan Bende.
There's no need to test the RPG; you shouldn't need to use, for example, the DistributeLoad processor. You should be able to have a GenerateFlowFile → RPG (with URL of any node) and then an input port going to some processor. The RPG figures out all of the nodes in the cluster and sends data to all of them.
If you go into the Remote Ports menu of the RPG, each port has some settings that control how many flowfiles get sent per transaction. Generally you will probably get a more even distribution with a smaller batch size, but you will get much better performance with a larger batch size. The RPG also factors in the number of flow files on each node when determining where to send them, so if node 1 is the primary node and has more flow files queued, then the RPG will likely send more flow files to node 2.
One reason to run an external Zookeeper in production mode is to prevent trouble arising when Zookeeper cannot establish a "quorum." This will keep a two-node cluster from starting up, for instance.
Keeping in the embedded Zookeeper nevertheless, to start the cluster, remove the server.2 line from zookeeper.properties on node 1; on node 2, set the nifi.state.management.zookeeper.start property (in nifi.properties) to false. Thereafter, as long as node 1 is started first, node 2 will start also.
The scenario above is obviated by an external Zookeeper or by adding a third node to the cluster.
Note that, unless coded to do so, a processor doesn't just stop working because a flowfile running through it happened to produce a failure. Others in the queue behind it will flow when they get their turn.
The processor will retry the failed flowfiles (whose original is left behind in the queue) after a penalty period of 30 seconds. This value is configurable in the processor's Settings → Penalty Duration.
Meanwhile, other, "innocent" files continue to make their way through the processor. The processor isn't summarily halted unless it's coded to halt at first failure.
Reminder...
In conf/nifi.properties, there is a variable, nifi.variable.registry.properties, that supports a comma-delimited list of file locations. See notes, Friday, 24 March 2017.
Just a note...
NiFi's conf subdirectory is not on any processor's classpath.
The conf subdirectory is on the class path of the system class loader when NiFi is launched. The class hierarchy is something like this:
The classpath of the system class load should be what you see in logs/nifi-bootstrap.log for the command that launched NiFi.
How to set up httpd/conf.d/nifi.conf (or /etc/apache2/sites-available/nifi.conf to run behind a reverse proxy server:
ProxyPass / http://hostname or address:8080/ ProxyPassReverse / http:/hostname or address:8080/ RequestHeader add X-ProxyScheme "http" RequestHeader add X-ProxyHost "hostname or address" RequestHeader add X-ProxyPort "80" RequestHeader add X-ProxyContextPath "/"
From Joe Witt...
NiFi can handle very small and very large datasets very well today. It has always been the case with NiFi that it reads data from its content repository using input streams and writes content to its content repository using output streams. Because of this, developers building processors can design components which pull in 1-byte objects just as easily as it can pull in 1Gb objects (or much more). The content does not ever have to be held in memory in whole except in those cases where a given component is not coded to take advantage of this.
Consider a process which pulls data via SFTP or HTTP or some related protocol. NiFi pull data from such an endpoint is streaming the data over the network and writing it directly to disk. We're never holding that whole object in some byte[] in memory. Similarly, when large objects move from processor to processor we're just moving pointers.
In fact, NiFi can even handle cases like merging content together very well for the same reason. We can accumulate a bunch of source content/flowfiles into a single massive output and do so having never held it all in memory at once.
Now, where can memory trouble happen? It can happen when the number of flowfile objects (the metadata about them—not the content) are held in memory at once. These can accumulate substantially in certain cases like splitting data for example. Consider an input CSV file with 1,000,000 lines. One might want individual lines so they can run specific per event processes on it. This can be accomplished in a couple ways.
Been looking at Kafka of late. Other than a missing, nice user interface like NiFi's, what is the real distinction? The one is message-queueing (Kafka) and the other a flow-control framework (NiFi).
If NiFi is providing all that's needed then Kafka isn't prescribed. However, Kafka offers an important capability in a broad, enterprise-requirement sense, the provision of a highly durable and replayable buffer of insertion ordered data for efficient access.
We saw this once:
2017-07-25 23:23:31,148 WARN [main] org.apache.nifi.web.server.JettyServer
Failed to start web server... shutting down.
org.apache.nifi.encrypt.EncryptionException:
org.jasypt.exceptions.EncryptionOperationNotPossibleException
at
org.apache.nifi.encrypt.StringEncryptor.decrypt(StringEncryptor.java:149)
~[nifi-framework-core-1.1.2.jar:1.1.2]
at
org.apache.nifi.controller.serialization.FlowFromDOMFactory.decrypt(FlowFromDOMFactory.java:474)
~[nifi-framework-core-1.1.2.jar:1.1.2]
.
.
.
The problem solution was found based on a quickly answered suggestion by Mark Payne:
Our Ansible instructions upgraded NiFi and created a new nifi.sensitive.props.key. In nifi.properties this property, if extant, is used to encrypt sensitive properties in flow.xml.gz. Thus, upon relaunching NiFi, the wrong key was used to decrypt resulting in the reported failure to start, flow.xml.gz is no longer useful.
How did we solve it?
We looked in the nifi.properties.rpmsave file, what RPM does with a file it's changed, and copied the old key from this property to paste in over the newly generated key in nifi.properties. Relaunched, NiFi worked with no problem. The full solution, in our case, is to insist in Ansible that it not generate for and replace nifi.sensitive.props.key with a new key.
Peter Wicks wrote this in the forum. I decided to copy it here for safe-keeping.
These tests ran on a single NiFi instance, with no clustering and are not designed to say anything about clustering.
Based upon my limited test results, a processor class is never reinstantiated unless the processor is deleted from the flow (... yea, kind of like cheating) or NiFi restarts.
If you have multiple versions of the same processor loaded into your flow (applicable only to 1.3, or perhaps 1.2?), you will also see the processor class reinstantiated when you right-click on a processor and choose to change the version.
According to Joe Witt, the most common sources of memory leaks in custom processors are
Jow Witt on NiFi site-to-site:
There are practical limits on how many input ports there can be. Each port generates threads to manage those sockets. However, many different edge systems can send to a single input port. You can also demultiplex the streams of data using flowfile attributes, so there are various ways to tackle that. It wasn't tested against thousands of edge systems sending to a central cluster as the more common model in such a case is less of tons of spokes and one central hub rather with spokes sending to regional clusters which send to central cluster(s).
Site-to-site has load balancing and fail-over built into it. The site-to-site exchange that happens when the connection is established and over time is to share information about the cluster, how many nodes are in it and their relative load. This allows the clients to do weighted distribution, detect new or removed nodes, etc.
You don't have to use the same version. This is another benefit of site-to-site is that it was built with the recognition that it is not possible or even desirable to upgrade all systems at once across a large enterprise. The protocol involves both sides of site-to-site transfers to exchange information about the flowfile/transfer protocol it supports. So old NiFi sending to new NiFi and new NiFi sending to an old NiFi are able to come to basic agreement. The protocol and serialization have been quite stable but still the ability to evolve is baked in.
To get ComponentLog output to stdout during unit testing of custom processors, you can configure this in src/test/resources/logback.xml, likely not already present. However, you also need to add
<dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> <scope>test</scope> </dependency>
Contents for src/test/resources/logback.xml might look like this:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-4r [%t] %-5p %c - %m%n</pattern>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>./target/log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
<logger name="org.apache.nifi" level="INFO" />
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
Caveat: This is not true for the Apache NiFi ComponentLog, but only for non-component log use. Please see Logging in NiFi for more detail.
As soon as it showed up in the downloads, I grabbed NiFi 1.4.0 to check it out. One of the new, cool features is variables. There's no documentation yet, but I reached them by right-clicking on a process group, choosing Variables, then adding one just for fun. My process group is named Poop:
NiFi variables can be referenced from situations in which the NiFi Expression Language is being used. It appears to me that, missing a variable at one level (process group), NiFi will crawl up the hierarchy (of process groups) until it finds it. This is in addition to NiFi's environment variable (registry) capability which can also be referenced from the NiFi Expression Language.
In this example, we have a list of log files that we're reading periodically one line at a time. We want to keep our place in each file, that is, the last line we've already read. We key this information off the logfile path, which is discrete no matter how many different ones there are since these are different pathnames in the filesystem.
/**
* Return the last line processed for the given file in order to be able to
* start on the line after this one.
* @param context current NiFi processor context.
* @param pathname of log file.
* @throws IOException in case of some disappointment.
*/
protected long getLastLineProcessed( final ProcessContext context, final String pathname )
throws IOException
{
StateMap localState = context.getStateManager().getState( Scope.LOCAL );
String lastLine = localState.get( pathname );
return( lastLine != null ) ? Long.parseLong( lastLine ) : 0L;
}
/**
* Save last line processed for the given file.
* @param context current NiFi processor context.
* @param pathname of log file.
* @param line last line processed: next time, start after this point.
* @throws IOException in case of some disappointment.
*/
protected void saveLastLineProcessed( final ProcessContext context, final String pathname, long line )
throws IOException
{
StateMap localState = context.getStateManager().getState( Scope.LOCAL );
Map< String, String > copyOfLocalState = localState.toMap();
int stateSize = ( copyOfLocalState.size() > 0 ) ? copyOfLocalState.size() : 1;
Map< String, String > newState = new HashMap<>( stateSize );
newState.putAll( copyOfLocalState );
newState.put( pathname, line+"" );
context.getStateManager().setState( newState, Scope.LOCAL );
}
How it works:
The state is held as a single map. In that map, there is information, each a string, each keyed by some string. The map can only replaced as a whole, so get it, manage the whole, and replace the whole.
Someone asserted that, whenever the number of processors in their flow exceeded something like 1500, the whole instance of NiFi slowed down noticeably and the UI became unresponsive.
Michael Moser wrote back pointing out that any time processors find themselves in the STOPPED state, NiFi is nevertheless performing validation on them including all their controller services. This would have the effect of slowing the UI.
A better solution to this problem is to put the unused processors into the DISABLED state as NiFi skips validation of processors in this or the RUNNING states.
A disabled processor appears thus:
It's put into this state by unclicking the Enabled checkbox:
IT is having trouble with NiFi on a server. There are bunch of files under work that don't exist. Here's NiFi 0.7.4 installation before running. Notice that there's no logs nor work subdirectory:
russ@nargothrond ~/dev/nifi $ ll nifi-0.7.4/
total 156
drwxrwxr-x 6 russ russ 4096 Jun 5 15:28 .
drwxr-xr-x 6 russ russ 4096 Nov 9 08:56 ..
drwxrwxr-x 2 russ russ 4096 Jun 5 15:28 bin
drwxrwxr-x 2 russ russ 4096 Jun 5 15:28 conf
drwxrwxr-x 3 russ russ 4096 Jun 5 15:28 docs
drwxrwx--- 3 russ russ 4096 Jun 5 15:28 lib
-rw-r--r-- 1 russ russ 79054 Jun 5 14:31 LICENSE
-rw-r--r-- 1 russ russ 42601 Jun 5 14:31 NOTICE
-rw-r--r-- 1 russ russ 4549 Jun 5 14:31 README
After launching, these files exist...
russ@nargothrond ~/dev/nifi/nifi-0.7.4 $ ./bin/nifi.sh start Java home: /home/russ/dev/jdk1.8.0_144 NiFi home: /home/russ/dev/nifi/nifi-0.7.4 Bootstrap Config File: /home/russ/dev/nifi/nifi-0.7.4/conf/bootstrap.conf 2017-11-09 08:59:48,822 INFO [main] org.apache.nifi.bootstrap.Command Starting Apache NiFi... 2017-11-09 08:59:48,822 INFO [main] org.apache.nifi.bootstrap.Command Working Directory: /home/russ/dev/nifi/nifi-0.7.4 2017-11-09 08:59:48,822 INFO [main] org.apache.nifi.bootstrap.Command Command: /home/russ/dev/jdk1.8.0_144/bin/java -classpath /home/russ/dev/nifi/nifi-0.7.4/./conf :/home/russ/dev/nifi/nifi-0.7.4/./lib/nifi-runtime-0.7.4.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/nifi-documentation-0.7.4.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/slf4j-api-1.7.12.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/nifi-api-0.7.4.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/jcl-over-slf4j-1.7.12.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/log4j-over-slf4j-1.7.12.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/jul-to-slf4j-1.7.12.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/logback-core-1.1.3.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/logback-classic-1.1.3.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/nifi-nar-utils-0.7.4.jar :/home/russ/dev/nifi/nifi-0.7.4/./lib/nifi-properties-0.7.4.jar -Dorg.apache.jasper.compiler.disablejsr199=true -Xmx512m -Xms512m -Dsun.net.http.allowRestrictedHeaders=true -Djava.net.preferIPv4Stack=true -Djava.awt.headless=true -Djava.protocol.handler.pkgs=sun.net.www.protocol -Dnifi.properties.file.path=/home/russ/dev/nifi/nifi-0.7.4/./conf/nifi.properties -Dnifi.bootstrap.listen.port=36755 -Dapp=NiFi -Dorg.apache.nifi.bootstrap.config.log.dir=/home/russ/dev/nifi/nifi-0.7.4/logs org.apache.nifi.NiFi russ@nargothrond ~/dev/nifi/nifi-0.7.4 $ ll work/jetty/ total 44 drwxrwxr-x 11 russ russ 4096 Nov 9 08:59 . drwxrwxr-x 5 russ russ 4096 Nov 9 08:59 .. drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-image-viewer-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-jolt-transform-json-ui-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-standard-content-viewer-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-update-attribute-ui-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-web-api-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-web-content-viewer-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-web-docs-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-web-error-0.7.4.war drwxrwxr-x 4 russ russ 4096 Nov 9 08:59 nifi-web-ui-0.7.4.war
After halting, these files disappear...
russ@nargothrond ~/dev/nifi/nifi-0.7.4 $ ./bin/nifi.sh stop Java home: /home/russ/dev/jdk1.8.0_144 NiFi home: /home/russ/dev/nifi/nifi-0.7.4 Bootstrap Config File: /home/russ/dev/nifi/nifi-0.7.4/conf/bootstrap.conf 2017-11-09 09:01:47,148 INFO [main] org.apache.nifi.bootstrap.Command Apache NiFi has accepted the Shutdown Command and is shutting down now 2017-11-09 09:01:47,220 INFO [main] org.apache.nifi.bootstrap.Command NiFi has finished shutting down. russ@nargothrond ~/dev/nifi/nifi-0.7.4 $ ll work/jetty/ total 8 drwxrwxr-x 2 russ russ 4096 Nov 9 09:01 . drwxrwxr-x 5 russ russ 4096 Nov 9 08:59 ..
This is happening because NiFi is failing to start up after some damage IT's synchronization script has done to the installation. I'm guessing it's the flow.xml.gz file, but they're sending me a scrap of
The solution turned out to be to remove the repositories. Likely, it was only necessary to remove the flowfile repository, but they removed all of them.
According to Joe Witt, if "the provenance repository [is] in a live-lock state with one of its threads, the getSize() call it [may be] sitting on has been seen before and fixed for some cases but perhaps not all. There is a whole new provenance repository you could switch to [...] [that] offers far faster and possibly more stable behavior called the WriteAheadProvenanceRepository. You can switch to it and it will honor the old data I believe. To switch you just edit conf/nifi.properties and where it says PersistentProvenanceRepository you change that classname to WriteAheadProvenanceRepository."
There really are 2 ways to do batching: calling session.get( n ) and using the @SupportsBatching annotation. When that annotation is present, what happens is that the framework will handle all of the batching for you. So you can just do FlowFile flowfile = session.get() and not even worry about batching at all. Especially, this means that the user is also able to choose how much batching should occur.
Construct PropertyDescriptor.Builder().expressionLanguageSupported() is deprecated, at least as early as NiFi v1.7.1.
| FLOWFILE_ATTRIBUTES | usually old true value |
| VARIABLE_REGISTRY | new semantic |
| NONE | old false |
I need this to say when our custom processor properties do support the NiFi Expression Language. It turns out that modernly, this is the way to do it:
public static final PropertyDescriptor PROPERTY_NAME = new PropertyDescriptor.Builder()
...
.expressionLanguageSupported( ExpressionLanguageScope.* )
.build();
...* where ExpressionLanguageScope is one of
It appears from line 195 of PropertyDescriptor.java that the default is NONE, so I don't have to specify this. I just have to analyse, case by case, whence the possible expression-language source and influence of values for the property might come. Before modern times, this was just a bit more mysterious. Now, hierarchically, this works like so:
In reference to writing custom processors, they are principally of two sorts.
If expecting an incoming flowfile, just return after checking (for a null flowfile). That way, onTrigger() will just try getting a flowfile over and over again until it finally gets one.
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.get();
if( flowfile == null )
{
context.yield();
return;
}
// handle the flowfile...
If the plan is not to provide an input (flowfile) to a (custom) processor and, instead, run it on cron or timer, do session.create() at the top of onTrigger(). This will create a new flowfile.
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.create();
// do special work...
Let's discuss back-pressure (even though I'm not actively developing with NiFi these days—I just want to get this into my notes to be able to refer others to it).
Back pressure is the concept in NiFi by which queue size (in front of a processor) is reduced in order to avoid overrunning the consuming processor with data. The number of flowfiles in the queue, before back-pressure is applied, is the back-pressure object threshold. Another configuration is the back-pressure data-size threshold. It's the maximum amount of data that can live in the queue (by counting the size the flowfiles represent) before applying back pressure.
You are using (for instance), GetFile to create flowfiles out of the filesystem. You configure an object threshold of 100 items on the queue to which GetFile routes its output. Whatever the processor consuming from that queue, whatever it does and however fast it's able to do it, if the count of items in the queue reaches 100, GetFile will no longer be allowed to run until the number drops back below 100.
If instead data size is the factor of quantity, then the total size of all flowfiles in the queue is what determines whether and when back pressure is applied. If set to 100Mb, the GetFile will be halted once the queue size has reached that limit no matter how many flowfiles that represents (1×100Mb flowfile or 100×1Mb flowfiles).
Back pressure is a way to respond to down-stream processors that are observed as taking longer to process in order to slow down, in some cases, to balance the source components so that they don't produce more data than can be consumed.
nifi.nar.library.directory=./lib nifi.nar.library.directory.custom=./custom-lib
Note that the observance by NiFi of a custom library subdirectory began in NiFi 1.0.
For best results, consult the official, Upgrading NiFi documentation. See also, Migration Guidance.
There have been numerous changes even within NiFi 1.x releases. Each step forward will require careful attention. Each NiFi release is accompanied by migration guide statements.
Once the number of flowfiles in a connection queue reaches the threshold set, it is removed from a hash map in the Java heap space and moved to disk? In which repository is this?
Swap files are written under the flowfile repository, in a subdirectory named swap. It was once, but is no longer configurable.
When a queue has flowfiles in it, the content of those flowfile is not in memory in the queue, it's just Java objects representing the pointers to the flowfiles.
Swapping is to help with memory when you have too many java objects. The information about what was in the queue is written out to a swap file, but it's not the content of those flowfiles that's written out, but only metadata about the flowfile; this is why it's in the flowfile repository.
For what repositories exist and the role each plays, see NiFi repositories.
A Registry client is configured in NiFi that contains the information needed for NiFi to connect to the registry. Assets, that is, flow definitions or extensions, are persisted or retrieved to or from the registry instance over HTTP(S). See
What's important about the NiFi Registry? It can be used to maintain a NiFi Process Group under version control!
This is a set of quick-start instructions. The registry is a service that you run to help NiFi.
Running in a cluster, a node goes down and, when it comes back up, the contents of some queued flowfiles have gone missing (unable to view content from the content viewer in the UI). What steps to take to correct this situation for the node?
Because running a cluster, the flow of the affected node needs only to be deleted. Once restarted, flow.xml.gz will be resynchronized from the other nodes in the cluster.
Note that the syntax expressing cron controls is not normal syntax, but Quartz syntax. Here's a calculator: Cron Expression Generator & Explainer - Quartz
I have still never stumbled upon what to do about this—at very least, suppress this message in Maven.
[WARNING] Unable to create a ClassLoader for documenting extensions. If this NAR contains
any NiFi Extensions, those extensions will not be documented.
Enable mvn DEBUG output for more information (mvn -X).
[WARNING] NAR will not contain any Extensions' documentation
- no META-INF/extension-manifest.xml file found!
Style control for additionalDetails.html: I wanted it not to use the ugly serif-based font it was using, but instead use the font of the pane on the left side of the displayed window (under NiFi Documentation). I tried to include NiFi's own main.css or component-usage.css, but it was hard to find the path to use and, when that worked, it tore away my own contruction (lists, numbering, etc.). What did work for me was to observe NiFi's styles (in those two files) and just use them directly.
To use logback configuration in JUnit testing, put the following, modified for what you want, into src/test/resources/logback-test.xml. This will supercede the production logback.xml configuration.
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-4r [%t] %-5p %c{3} - %m%n</pattern>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>./target/log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
<logger name="org.apache.nifi" level="INFO" />
<logger name="org.apache.nifi.security.util.crypto" level="DEBUG" />
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
I had a case where I decided that the best way to handle an incoming flowfile was to process the first part in such a way as to preserve it out to the flowfile intact and unchanged, but then process the other "half" of the flowfile using a SAX parser.
Shaky on reopening/rewinding/restarting input streams in Java and wondering what NiFi was doing underneath me, I posted a question.
In short, I wanted to:
Several answers came back, but the one that worked for me, was more or less a brand-new session/flowfile pattern to implement:
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile original = session.get();
if( original == null )
{
context.yield();
return;
}
// create an output flowfile...
FlowFile output = session.create( original );
// begin writing to the output flowfile...
FlowFile modified = session.write( output, new OutputStreamCallback()
{
@Override
public void process( OutputStream outputStream )
{
// read from original flowfile and copy to the output flowfile
session.read( original, new InputStreamCallback()
{
@Override
public void process( InputStream inputStream ) throws IOException
{
copyFirstHalf( inputStream, outputStream );
}
} );
// (reopen the original flowfile)
// read from original flowfile a second time SAX-parsing it
// write what the SAX parsing, etc. produces to the end of the output flowfile...
// ...after what was written when the "first half" was copied
session.read( original, new InputStreamCallback()
{
@Override
public void process( InputStream inputStream ) throws IOException
{
processWithSaxParser( inputStream, outputStream );
}
} );
}
} );
session.transfer( modified, SUCCESS );
session.remove( original );
}
Why does this work?
Because we
When going to View data provenance, there are sometimes no logs.
Mark Payne says...
In ${NIFI_ROOT}/conf/nifi.properties, there are a couple of property named nifi.provenance.repository.max.storage.time that defaults to 24 hours Is it possible that you went 24 hours (or whatever value is set for that property) without generating any provenance events?
If so, it's trying to age off old data but unfortunately doesn't perform a check to determine whether or not the "old file" that it's about to delete is also the "active file."
NiFi now loads custom (and other) processors when needed without restarting its instance. This it to accommodate updated NARs. However, if you offer the same NAR, that is, with the same component version information in its manifest, you will not see work. You can only expect it to load new versions and show them in the UI. Often, a custom NAR will not change its manifest because the author hasn't gone to the trouble to make that happen. So, just changing the code of the NAR still isn't enough.
I was struggling with configuring UpdateAttribute. I was doing this:
format.type = ${ ${filename:endsWith( '.xml' )} : ifElse( 'XML', 'JSON' ) }
...but the result, despite the flowfile name being sample.xml, is that format.type always gets JSON. It's because (so a reply from [email protected] informed me):
format.type = ${filename:endsWith( '.xml' ) : ifElse( 'XML', 'JSON' )}
A few years ago, NiFi only offered the name field. The behavior was, however, that if this field ever changed (spelling, etc.), that would break the flow because it would fail to match what's recorded in flow.xml.gz.
So, it was devised to add displayName, which could be changed at will without effect upon flow.xml.gz in terms of breaking the processor's identity. This left name constant—and what is used in flow.xml—in order not to break backward-compatibility.
If you were to localize a processor with a property, the entity to change would be displayName while name must remain constant in order to be considered the same thing. Thus, ...
.name( "Press here" ) .displayName( "Press here" )
...while when localized in French, it would be:
.name( "Press here" ) .displayName( "Poussez ici" )
For the life of me, I could not come to grips with this problem.
If I have changed a custom processor's PropertyDescriptor.name and/or .displayName, including changes I have made to my additionalDetails.html, and I have:
...yet nothing changes (in usage or in additional details), what am I overlooking?
Let's set aside the vaguely confusing semantic distinction between name and displayName, I just want NiFi to forget my new custom processor completely and then accept my new version as if brand new including all the changes I have made.
The answer? Simpler than imaginable:
Have you verified this is not a browser caching issue? They are pernicious and it sounds like this could be an example. If you're sure it's not, verify the API calls using your browser's Developer Tools to see what properties are actually being returned by the server when inspecting a component to see if the correct values are present. If so, it's likely a UI bug, and if not, the new code is not being properly loaded/used by NiFi's server application.
In my case, it was a caching issue with Chrome. I don't know why I didn't think to try that—forest for the trees, I guess.
A simple way to overcome this is to kill the browser tab running the NiFi UI. Stop the NiFi instance also. Then, relauch it and, before it can come up sufficiently to support the UI (you will see "This site can't be reached" or something similar), hold down the Ctrl key as you click Reload.
Here's more or less a full implementation.
package com.windofkeltia.processor;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import static java.util.Objects.isNull;
import org.apache.nifi.annotation.behavior.DynamicProperty;
import org.apache.nifi.annotation.behavior.InputRequirement;
import org.apache.nifi.annotation.behavior.SideEffectFree;
import org.apache.nifi.annotation.documentation.CapabilityDescription;
import org.apache.nifi.annotation.documentation.Tags;
import org.apache.nifi.annotation.lifecycle.OnScheduled;
import org.apache.nifi.components.PropertyDescriptor;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.processor.AbstractProcessor;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.ProcessorInitializationContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.exception.ProcessException;
import org.apache.nifi.processor.util.StandardValidators;
/**
* Demonstration of NiFi dynamic properties. The preoccupations making up dynamic
* properties are the following and examples of each are in this code.
*
* 1. onTrigger() discovery (see comment in onTrigger()
* 2. overridden getSupportedDynamicPropertyDescriptor()
* 3. an @OnScheduled method can be written to examine any property include dynamic ones
*
* Facultative; only if you need a list of dynamic properties by name. This is not common and
* it seems vaguely silly, but this is how RouteOnAttribute works.
*
* 4. a variable to hold them, volatile Set< String >
* 5. overridden onPropertyModified()
*
* Behavior of this processor
*
* The flowfile contents are transferred straight across unchanged, but any
* dynamic property created becomes an attribute with its value as the value
* given the property and is passed along with the flowfile.
*
* @author Russell Bateman
* @since July 2020
*/
@InputRequirement( InputRequirement.Requirement.INPUT_REQUIRED )
@Tags( { "demonstration" } )
@CapabilityDescription( "No-operation processor that illustrates how to allow for and consume a dynamic property." )
@DynamicProperty( name = "property", value = "content", description = "Why you might wish to create this property." )
public class DynamicPropertyDemo extends AbstractProcessor
{
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
FlowFile flowfile = session.get();
if( flowfile == null )
{
context.yield();
return;
}
/* Here's how to reach the dynamic property: course through all properties and
* look only at the dynamic ones. (Yes, this begs at least a couple of questions,
* but the answer is context-sensitive: What sort of property(ies) do you expect?
* and just what do you wish to do with them?) Here, we want to create a new
* flowfile attribute for each dynamic property we find and transfer the property's
* value over to the new attribute as its value.
*/
for( Map.Entry< PropertyDescriptor, String > entry : context.getProperties().entrySet() )
{
PropertyDescriptor property = entry.getKey();
if( !property.isDynamic() )
continue;
flowfile = session.putAttribute( flowfile, property.getName(), entry.getValue() );
}
session.transfer( flowfile, SUCCESS );
}
/**
* This method is overridden from AbstractConfigurableComponent.
*
* In allowing a user to define a dynamic property, which is to say
* one that is not known statically (as are most processor properties), we
* override this method to create that property allowing us also to specify
* a validator. Without doing this, we'll always get something like:
*
* java.lang.AssertionError: Processor has 1 validation failures:
* (dynamic-property-name) validated against (its value) is invalid because\
* (dynamic-property-name) is not a supported property or has no Validator associated with it
*
* @param propertyDescriptorName the name of the property's descriptor.
* @return the new descriptor.
*/
@Override
protected PropertyDescriptor getSupportedDynamicPropertyDescriptor( final String propertyDescriptorName )
{
return new PropertyDescriptor.Builder()
.required( false )
.name( propertyDescriptorName )
.addValidator( StandardValidators.NON_EMPTY_VALIDATOR )
// or .addValidator( Validator.VALID ) if you do not wish it validated!
.dynamic( true )
.build();
}
/**
* Used with onPropertyModified(), it collects dynamic properties
* that change. This is not common.
* See {@link #onPropertyModified( PropertyDescriptor, String, String )}
*/
private volatile Set< String > dynamicPropertyNames = new HashSet<>();
/**
* This method is overridden from AbstractConfigurableComponent. It's
* called in reaction to a configuration change (in the UI).
*
* Why might you want to do this? Because you are using dynamic properties to
* influence the set of relationships that a processor may have, adding to or
* subtracting from them. For example, if we were called with "dynamic-property"
* added, then this method would add a new relationship (to SUCCESS)
* called "dynamic-property" (--for whatever good that might do).
*
* This is not a common thing to do.
*
* @param descriptor of the modified property.
* @param oldValue non-null: previous property value.
* @param newValue new property value or null when property removed (trash can in UI).
*/
@Override
public void onPropertyModified( final PropertyDescriptor descriptor, final String oldValue, final String newValue )
{
final Set< String > newDynamicPropertyNames = new HashSet<>( dynamicPropertyNames );
if( isNull( newValue ) )
newDynamicPropertyNames.remove( descriptor.getName() );
else if( isNull( oldValue ) && descriptor.isDynamic() )
newDynamicPropertyNames.add( descriptor.getName() );
dynamicPropertyNames = Collections.unmodifiableSet( newDynamicPropertyNames );
final Set< String > allDynamicProperties = dynamicPropertyNames;
final Set< Relationship > newRelationships = new HashSet<>();
newRelationships.add( SUCCESS ); // don't forget to add back in the static relationship we started with!
for( final String propName : allDynamicProperties )
newRelationships.add( new Relationship.Builder().name( propName ).build() );
relationships = newRelationships;
}
/**
* When the processor is scheduled, you can access its properties including
* any dynamic ones.
* @param context processor context.
*/
@OnScheduled public void processProperties( final ProcessContext context )
{
for( final PropertyDescriptor descriptor : context.getProperties().keySet() )
{
if( descriptor.isDynamic() )
getLogger().debug( "Dynamic property named: " + descriptor.getName() );
}
}
public static final Relationship SUCCESS = new Relationship.Builder()
.name( "Success" )
.description( "Pass the flowfile on (without modification or copying)." )
.build();
private List < PropertyDescriptor > properties;
private Set< Relationship > relationships;
@Override
public void init( final ProcessorInitializationContext context )
{
@SuppressWarnings( "MismatchedQueryAndUpdateOfCollection" )
List< PropertyDescriptor > properties = new ArrayList<>();
this.properties = Collections.unmodifiableList( properties );
Set< Relationship > relationships = new HashSet<>();
relationships.add( SUCCESS );
this.relationships = relationships;
this.relationships = Collections.unmodifiableSet( relationships );
}
@Override public List< PropertyDescriptor > getSupportedPropertyDescriptors() { return properties; }
@Override public Set< Relationship > getRelationships() { return relationships; }
}
package com.windofkeltia.processor;
import java.io.ByteArrayInputStream;
import java.util.List;
import java.util.Map;
import org.junit.After;
import org.junit.Before;
import org.junit.Rule;
import org.junit.Test;
import org.junit.rules.TestName;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotNull;
import static org.junit.Assert.assertTrue;
import org.apache.nifi.util.MockFlowFile;
import org.apache.nifi.util.TestRunner;
import org.apache.nifi.util.TestRunners;
import com.windofkeltia.utilities.StringUtilities;
import com.windofkeltia.utilities.TestUtilities;
public class DynamicPropertyDemoTest
{
@Rule public TestName name = new TestName();
@Before public void setUp() { TestUtilities.setUp( name ); }
@After public void tearDown() { }
private static final boolean VERBOSE = TestUtilities.VERBOSE;
private static final int ONE = 1;
private static final String CONTENT = "This is a test of the Emergency Broadcast System. It is only a test.";
private static final String PROPERTY = "dynamic-property";
private static final String VALUE = "this is its value";
@Test
public void test()
{
TestRunner runner = TestRunners.newTestRunner( new DynamicPropertyDemo() );
// how you create a dynamic property running under the NiFi JUnit test framework...
runner.setValidateExpressionUsage( false );
runner.setProperty( PROPERTY, VALUE );
runner.enqueue( new ByteArrayInputStream( CONTENT.getBytes() ) );
runner.run( ONE );
runner.assertQueueEmpty();
List< MockFlowFile > flowfiles = runner.getFlowFilesForRelationship( DynamicPropertyDemo.SUCCESS );
assertEquals(1, flowfiles.size() );
MockFlowFile flowfile = flowfiles.get( 0 ); assertNotNull( flowfile );
String content = new String( runner.getContentAsByteArray( flowfile ) );
Map< String, String > attributes = flowfile.getAttributes();
assertTrue( attributes.containsKey( "dynamic-property" ) );
if( VERBOSE )
{
System.out.println( "- Attributes -------------------------------------------------------------------------" );
int keyWidth = 0;
for( Map.Entry< String, String > attribute : attributes.entrySet() )
keyWidth = Math.max( keyWidth, attribute.getKey().length() );
for( Map.Entry< String, String > attribute : attributes.entrySet() )
System.out.println( " " + StringUtilities.padStringLeft( attribute.getKey(), keyWidth )
+ " = " + attribute.getValue() );
System.out.println( "- Content ----------------------------------------------------------------------------" );
System.out.println( CONTENT );
}
}
}
Output from running test above:
218 [main] DEBUG c.w.p.DynamicPropertyDemo.debug:165 - DynamicPropertyDemo[id=89aae310-eb3f-408d-a702-799599bf5bb3] Dynamic property named: dynamic-property
- Attributes ----------------------------------------------------------------------------
path = target
filename = 2528507558493164.mockFlowFile
uuid = 4ae2af73-ae6f-432a-8a61-a212bdea90d8
dynamic-property = this is its value
- Content -------------------------------------------------------------------------------
This is a test of the Emergency Broadcast System. It is only a test.
Can't find your new custom processor when you go to use it in NiFi? Try this:
NiFi Parameters arose in NiFi 1.10.0. Parameter Context is a named set of parameters with applied access policies at the controller level. It doesn't belong to any individual process group, but is globally defined (à la différence of the NiFi Variable Registry which is now deprecated and which NiFi Parameters replaces).
A parameter context may only be created and added to by users with appropriate permissions. Sensitive properties, which were not supported by NiFi Variables, are accessed by sensitive parameters. Non-sensitive properties can only be accessed by non-sensitive parameters.
NiFi Parameter references appear thus: #{parameter-name}.
Parameters are defined and maintained including deleted from Parameter Context under the hamburger menu in the UI. In NiFi Parameter Contexts, you click the + sign to add a new parameter. You can add a Description to remind of the parameter's purpose.
Typically, for example, in a given installation, there might be Development, Staging and Production flows (hardware, NiFi instances, etc.). Let's imaging we're juggling multiple configuration files defining which database and tables to use and sensitive information like a username and password. Ignoring the database mentioned here and ignoring the concept of staging and production, let's set up a simple implementation of keeping username and password as parameters:
Repeat the above for a second context, perhaps "Production" or even a third to make the rest of the example worthwhile here.
Obviously, the choice of the parameter name is paramount. It must disambiguate any potential use (username for what? password for what?). "Username" and "password" chosen here would not be really good parameter names. Second, the parameters whose only difference is the context they belong to must be identical.
Parameter contexts and parameters appear in NiFi, as you see here, a little like controller configuration. Both are global configuration properties. Were we to pursue this example fully, we would have three contexts listed:
How will each context be discerned? Each processor group is configured for properties (just as each processor is configured). After the Process Group Name, Process Group Parameter Context is configured using a drop-down.
Anywhere we wish to make use of parameters username and password, wherever the NiFi Expression Language allows this (for example, as the value of a property in a processor's configuration, we can just type #{username} or #{password}. These values will change according to the parameter context of the owning process group.
No, it doesn't appear that changing parameter context for a top-level process group affects the context that's set for deeper process groups.
Monitoring is something that hasn't been overwhelmingly welcomed by NiFi users even though they're complaining annoys me given that any other system, for example, the use of queueing software like RabbitMQ or even Kafka, not to mention just writing a pile of intermediate processors to send flow objects through, presents near-zero help.
Scroll down to see 3. Back Pressure Prediction in Parameter Context, Retry FlowFile & Back Pressure Prediction in NiFi-1.10 Release.
If you introduce a new version of a processor through NiFi (whether through the official extensions library, or the hot-loading /extensions subdirectory), the existing processors in the flow do not change by themselves. Rather, they become an available option from a Change Versions element in their context menu. The processor does need to be stopped to do this, but any loaded version can be used, even to downgrade to a more stable variant. If the properties of a processor change, anything removed gets left behind as a custom entry, rather than deleted, and new properties are created for you.
If you update the processor package to a new version and then delete the old, and restart NiFi to enforce the change, NiFi will search for any available versions of the same processor to update, or downgrade, automatically the processor with the bad version.
What happens if you have other versions, but not the present one? Use the latest?
The NiFi Registry does care what version a processor is, how does it behave if the desired version isn't present while other versions are?
Changing the Java package for a class (in the case of writing custom processors) makes NiFi very angry. If a refactor like that is necessary, every instance using that processor in a flow will need to be redone because NiFI won't associate the processor classes with the new packages.
Subordinate NARs can be versioned separately from the parent NAR.
Notice that, in IntelliJ IDEA's debugger, the flowfile object (comes from toString()) appears thus:
public String toString()
{
return "FlowFile[" + this.id + ","
+ this.getAttribute(CoreAttributes.FILENAME.key()) + ","
+ this.getSize() + "B]";
}
How to do session read() or write() I/O to create two, new flowfiles from one? See this code: A second custom processor example.
The code to simulate a queue in front of a processor in JUnit. I'm looking for two files to glue (merge) back together. They must have each share a common id. Here, we're simulating a queue with a bunch of files—only two of which interest our processor. We're intentionally trying to be perverse; the bogus flowfiles should not be routed to us, but stuff like this could happen. I'm not showing the content to be merges—it's not important.
@Test
public void test()
{
final Map< String, String > FIRSTHALF_ATTRIBUTES = new HashMap<>();
final Map< String, String > SECONDHALF_ATTRIBUTES = new HashMap<>();
FIRSTHALF_ATTRIBUTES.put( "firsthalf-uuid" "12345" );
SECONDHALF_ATTRIBUTES .put( "secondhalf-uuid", "12345" );
runner.enqueue( new ByteArrayInputStream( "This is a bogus, non-participating flowfile (1)".getBytes() ) );
runner.enqueue( new ByteArrayInputStream( FIRSTHALF_CONTENT.getBytes() ), FIRSTHALF_ATTRIBUTES );
runner.enqueue( new ByteArrayInputStream( "This is a bogus, non-participating flowfile (2)".getBytes() ) );
runner.enqueue( new ByteArrayInputStream( "This is a bogus, non-participating flowfile (3)".getBytes() ) );
runner.enqueue( new ByteArrayInputStream( "This is a bogus, non-participating flowfile (4)".getBytes() ) );
runner.enqueue( new ByteArrayInputStream( SECONDHALF_CONTENT.getBytes() ), SECONDHALF_ATTRIBUTES );
runner.enqueue( new ByteArrayInputStream( "This is a bogus, non-participating flowfile (5)".getBytes() ) );
runner.run( ONE );
.
.
.
The merging processor's onTrigger() goes down a little like this. This processor is the subject-under-test of the previous JUnit code.
public class Reassemble extends AbstractProcessor
{
public void onTrigger( final ProcessContext context, final ProcessSession session )
{
List< FlowFile > flowfiles = session.get( context.getProperty( BATCHSIZE ).asInteger() );
if( isNull( flowfiles ) || flowfiles.size() == 0 )
return;
FlowFile first = null, second = null;
for( FlowFile flowfile : flowfiles )
{
if( isNull( flowfileHasOurAnnotation( flowfile ) ) )
session.transfer( flowfile, UNPROCESSED );
if( nonNull( flowfile.getAttribute( "firsthalf-uuid" ) ) )
first = flowfile;
else if( nonNull( flowfile.getAttribute( "secondhalf-uuid" ) ) )
second = flowfile;
if( isNull( first ) || isNull( second ) )
continue;
String firstUuid = first.getAttribute( "firsthalf-uuid" );
String secondUuid = second.getAttribute( "secondhalf-uuid" );
if( !firstUuid.equals( secondUuid ) )
continue;
// process these two flowfiles into a single one...
// set a breakpoint here to see if we find the two that need pairing
// TODO: what happens if we reduce the batch size more and more?
// TODO: we would potentially divorce the two files one from the other to different batches...
// TODO: ...and fail!
session.remove( first ); first = null;
session.remove( second ); second = null;
}
}
/**
* If this returns null, then the flowfile should be routed down the
* UNPROCESSED relationship.
*/
private static String flowfileHasOurAnnotation( FlowFile flowfile )
{
String attribute = flowfile.getAttribute( "firsthalf-uuid" );
if( nonNull( attribute ) )
return attribute;
return flowfile.getAttribute( "secondhalf-uuid" );
}
A link: Using multiple FlowFiles as input to a processor
General recommended practices for tuning NiFi to handle flows that may drop several million small flowfiles (2K-10K each) onto a single node.
For many flowfiles, it's best to have separate disks set up for data provenance. There are issues related to the ability of provenance to keep up. Creating three separate disks and changing the accompanying configuration helps a great deal.
It's a good idea to make some changes around threading too, information on this at HDF/CFM best practices for setting up a high-performance NiFi installation.
Regarding the Maximum Timer Drive Thread Count, the default is quite low (depending on size of executing host). There is a best-practices document. It is possible to set this to 2-4 times the number of cores on the host. Some have set it aggressively to 4 after which some processors began to run multiple thread. It is only necessary to watch that no set of processors eat up all the available cycles.
Apache NiFi Anti-patterns videos. For general NiFi videos, google "youtube Apache NiFi."
If a processor seems "stuck" or "hung," the best course of actions is to get a thread dump:
$ bin/nifi.sh dump thread-dump-name.txt
The thread dump will show what the processor is doing at that time which may lead to understanding why it's hung.
There is an Apache NiFi users mail thread dated 23 November 2020 that stretches over the next few days discussing Tuning for flow with lots of processors covering using 2000 processors running on a single node and slowness, the effect of increasing the number of timer-driven threads.
Apache NiFi Anti-Patterns Part 4 - Scheduling
Back-pressure was brought up. In general, if backpressure is being applied, the destination of that connection is the bottleneck. If multiple connections in sequence have backpressure applied, look to the last one in the chain, as it's causing the back-pressure to propagate back.
Eventually, disk space comes up and several settings...
nifi.bored.yield.duration
nifi.content.repository.archive.max.usage.percentage=50%
If looking at logs and seeing "Unable to write to container XYZ due to archive
file size constraints; waiting for archive cleanup," it's perhaps the
content repository is applying back-pressure to keep from running out of
disk space. More disk is needed, though it's possible to risk increasing the
setting to 90% with commensurate danger.
The increase of disk space helped substantially.
Faced with trouble using logging during JUnit testing and NiFi, I wrote a higher-level mechanism, that I called NiFiLogger, to cover when the logger reported is null.
public class CustomProcessor extends AbstractProcessor
{
private final NiFiLogger logger = new NiFiLogger( getLogger() );
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.get();
.
.
.
if( logger.isDebugEnabled() )
...
Ultimately, however, I found this onerous and mendacious, so I discarded it. Doing that set me back to the old problem of getLogger() returning null. This was because the code to my custom processors tended to do this (and go boom when run under TestRunner!):
public class CustomProcessor extends AbstractProcessor
{
private final ComponentLog logger = getLogger();
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
FlowFile flowfile = session.get();
.
.
.
if( logger.isDebugEnabled() )
...
My higher-level mechanism worked fine, it ignored the null coming back from getLogger() and created/substituted running in JUnit a suitable logger—a lie, as I say, and now I'm getting rid of it. The secret is that insisting on getting the logger in-line as part of the definition of an instance variable won't work because the logger is given to the processor in an initialization method that hasn't been called at that point. Conversely, in production use, the logger would already be known and avaiable. So, here's how to do it the right way/best practice:
public class CustomProcessor extends AbstractProcessor
{
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session )
throws ProcessException
{
final ComponentLog logger = getLogger();
System.out.println( "NiFi ComponentLog = " + logger );
System.out.println( " name = " + logger.getName() );
FlowFile flowfile = session.get();
.
.
.
if( logger.isDebugEnabled() )
...
The output becomes:
NiFi ComponentLog = org.apache.nifi.util.MockComponentLog@6181b987
name = com.windofkeltia.processor.CustomProcessor
The log level for the custom processor is established by this paragraph in logback.xml. In normal production, this file exists on the path, ${NIFI_ROOT}/conf/logback.xml. Here's a custom logger set up to govern this:
<logger name="com.windofkeltia.processor" level="INFO" additivity="false"> <appender-ref ref="CONSOLE" /> </logger>
Note that this file would never contain such a custom paragraph without it being added. The point is that the package path to the custom processor (here the example is com.windofkeltia.processor) must match the processor whose logging concerns you.
Here's a minimal logback.xml:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-4relative [%thread] %-5level %logger{5}.%method:%line - %message%n</pattern>
</encoder>
</appender>
<logger name="org.apache.nifi" level="INFO">
<appender-ref ref="CONSOLE" />
</logger>
<!-- insert custom logger here... -->
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
When running JUnit tests, under the TestRunner, logback.xml goes of course, locally. There is a "pecking order." I tend to keep two copies around, test/resources/logback-test.xml and main/resources/logback.xml. (This second one is what I keep to remind me what I want to see as defaults when I deploy to a NiFi instance.)
The logback.xml used—in my observation—is prioritized thus:
I am thinking about batching and have read everything I can find. It's curious how many writers talk about how batching increases performance in NiFi, but no one says too much about why that is. Okay, reduced number of I/O operations, but is this in common with every possible use of NiFi (every possible type of flowfile) or just some types of use and not others?
I found an example of an almost "hello world" batching (custom) processor. I enhanced it slightly to make it more real and am posting it here. The original author was Andy Lo Presto.
import java.util.ArrayList;
import java.util.Collections;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Set;
import org.apache.nifi.annotation.behavior.SideEffectFree;
import org.apache.nifi.annotation.behavior.SupportsBatching;
import org.apache.nifi.annotation.behavior.TriggerSerially;
import org.apache.nifi.annotation.documentation.CapabilityDescription;
import org.apache.nifi.annotation.documentation.Tags;
import org.apache.nifi.components.PropertyDescriptor;
import org.apache.nifi.expression.ExpressionLanguageScope;
import org.apache.nifi.flowfile.FlowFile;
import org.apache.nifi.logging.ComponentLog;
import org.apache.nifi.processor.AbstractProcessor;
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.ProcessSession;
import org.apache.nifi.processor.ProcessorInitializationContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.exception.ProcessException;
import org.apache.nifi.processor.util.StandardValidators;
/**
* This example is Andy's (an Apache NiFi committer of long date) with
* very useful comments. From the URL here and other documentation...
* https://www.javadoc.io/doc/org.apache.nifi/nifi-api/1.12.0/org/apache/nifi/annotation/behavior/SupportsBatching.html
*
* @SupportsBatching: This annotation indicates that it is okay for the framework
* to batch together multiple ProcessSession commits into a single commit. If this
* annotation is present, the user will be able to choose whether they prefer high through-put
* or lower latency in the processor's Scheduling tab. This annotation should be
* applied to most processors, but it comes with a caveat: if the processor calls
* ProcessSession.commit(), there is no guarantee that the data has been safely
* stored in NiFi's Content, FlowFile, and Provenance Repositories. As a result, it is not
* appropriate for those Processors that receive data from an external source, commit
* the session, and then delete the remote data or confirm a transaction with a remote
* resource.
*
* @author Andy Lo Presto
* @since April 2019
*/
@SupportsBatching
@SideEffectFree
@TriggerSerially
@Tags( { "batch" } )
@CapabilityDescription( "Demonstrates processing batches of flowfiles." )
public class CustomBatchProcessor extends AbstractProcessor
{
private final ComponentLog logger = getLogger();
@Override
public void onTrigger( ProcessContext context, ProcessSession session ) throws ProcessException
{
// try to get n flowfiles from incoming queue...
final Integer desiredFlowfileCount = context.getProperty( BATCH_SIZE ).asInteger();
final int queuedFlowfileCount = session.getQueueSize().getObjectCount();
if( queuedFlowfileCount < desiredFlowfileCount )
{
// there are not yet n flowfiles queued up, so don't try to run again immediately
if( logger.isDebugEnabled() )
logger.debug( "Only " + queuedFlowfileCount + " flowfiles queued; waiting for " + desiredFlowfileCount );
context.yield();
return;
}
// if we're here, we do have at least n queued flowfiles
List< FlowFile > flowfiles = session.get( desiredFlowfileCount );
try
{
// TODO: perform work on all flowfiles...
for( int file = 0; file < flowfiles.size(); file++ )
{
// write the same timestamp value onto all flowfiles
FlowFile flowfile = flowfiles.get( file );
flowfiles.set( file, session.putAttribute( flowfile, "timestamp", "my timestamp value" ) );
}
session.transfer( flowfiles, SUCCESS );
/* If extending AbstractProcessor, this is handled for you and you do not explicitly
* need to commit. In fact, you should not: see Javadoc for this class.
session.commit();
*/
}
catch( Exception e )
{
logger.error( "Helpful error message here (?)" );
if( logger.isDebugEnabled() )
logger.error( "Further stacktrace: ", e );
/* Penalize the flowfiles if appropriate (done for you if extending AbstractProcessor
* and an exception is thrown from this method).
session.rollback( true );
*/
/* --- OR ---
* transfer to failure if they can't be retried.
*/
session.transfer( flowfiles, FAILURE );
}
}
public static final PropertyDescriptor BATCH_SIZE = new PropertyDescriptor.Builder()
.name( "Batch Size" )
.description( "The number of flowfiles per batch." )
.required( true )
.expressionLanguageSupported( ExpressionLanguageScope.FLOWFILE_ATTRIBUTES )
.addValidator( StandardValidators.INTEGER_VALIDATOR )
.defaultValue( "10" )
.build();
public static final Relationship SUCCESS = new Relationship.Builder()
.name( "success" )
.description( "All flowfiles are routed to success, eventually." )
.build();
public static final Relationship FAILURE = new Relationship.Builder()
.name( "failure" )
.build();
private List< PropertyDescriptor > properties;
private Set< Relationship > relationships;
@Override
public void init( final ProcessorInitializationContext context )
{
// create static properties and relationships...
List< PropertyDescriptor > properties = new ArrayList<>();
properties.add( BATCH_SIZE );
this.properties = Collections.unmodifiableList( properties );
Set< Relationship > relationships = new LinkedHashSet<>();
relationships.add( SUCCESS );
relationships.add( FAILURE );
this.relationships = Collections.unmodifiableSet( relationships );
}
@Override public Set< Relationship > getRelationships() { return relationships; }
@Override public List< PropertyDescriptor > getSupportedPropertyDescriptors() { return properties; }
}
Use this to ensure that, no matter what values a property has, including nothing at all, it validates:
public static final PropertyDescriptor DEFAULT_MAPPINGS = new PropertyDescriptor.Builder()
.name( "default mappings" )
.displayName( "Default mappings" )
.defaultValue( "" )
.addValidator( Validator.VALID )
.build();
Just confirming that name is the internal identifier by which the property is known. If it ever changes, this breaks backward compatibility with what's in flow.xml.gz and the updated processor will not be recognized as the same one being replaced.
Changing displayName works. It's what NiFi feeds to the UI, what's "displayed" and any change is ignored. So, if you misspell name, no matter, correct the spelling in displayName and your embarrassment is no more.
Discovered NiFi analytics today via Yolanda Davis.
Here's a quick clue to what's shown here. We enable analytics in nifi.properties, then launch. Hover mouse over the left side (object-count) of the bottom of a queue's box. Here's what you see:
Also by Yolanda, Apache NiFi 1.10—Back-pressure Prediction
I discovered that I can put additional HTML, CSS and image resources on the path, src/main/resources/docs/com.windofkeltia.processor.XyzProcessor alongside additionaResources.html to be consumed by this latter. I experimented placing a small logo (image) and consuming it. Then I rebuilt my NAR, deployed it, bounced NiFi (1.11.4) and took a look at Additional Details.... The image was there. I don't foresee heavy use of this revelation, but it's good to know. I wish there were a central location I could put my stylesheets I'm presently duplicating at the top of every additionalDetails.html.
I have a flow performing ETL of HL7v4 (FHIR) documents on their way to indexing and storage. Custom processors perform the important transformations. Performance of this flow is at a premium for us. At some point along the way I want to gate off copies of raw or of transformed FHIR records (the flow writer's choice) to a new flow (a "subflow" of the total flow) for the purpose of validating those FHIR records as an option.
The main ETL flow will thus not be interrupted. Also, its performance should not be too hugely impacted by this new subflow. I have looked at priority techniques discussed, but usually the discussion is geared more toward a resulting order. I want to deprecate the performance of this new subflow to avoid handicapping the main flow, ideally from almost shutting down the subflow to allowing it equal performance with the main ETL flow.
Are there recommendations for such a thing? As I author many custom processors, is there something I could be doing in my code to aid this? I want rather to put the amount of crippling into the hands of my flow writers a) by natural, existing configuration that's a feature of most NiFi processors and/or b) surfacing programming choices as configuration in my custom processor's configuration. Etc.
Mark Payne advised...
You can't really set a "priority" of one flow over the other. A couple of options that may make sense for you though:
Advice from Mark Payne...
Funnels generally are very fast. They don't have to read or write content. They don't update the Provenance Repository. They just update the FlowFile Repository and do so in batches of up to 1,000 at a time. That said, they are cheap but they are not free.
Consider that if you have 10 million flowfiles in each Relationship, that means you’re doing a lot of swapping. So it has to read/parse/deserialize all of those flowfiles that are swapped to disk, and then re-serialize/re-write them to swap files. That does get quite expensive. With smaller queues, it’s probably a couple orders of magnitude more efficient.
The point of funnels is really just to allow flowfiles from multiple queues to put into the same queue so that they can be prioritized. But it will definitely be more efficient, if they have swapped data, to skip the funnel.
You want to use PutFile to write flow files out to a network drive, but fail if the disk is not mounted.
Shawn Weeks suggests...
You could set the permissions on the unmounted folder where NiFi can't write to them since the permissions when mounted come from the NFS share. For example assume mounting to /mnt/nifi-dropoff...
Before mounting to that point create the directory and set the permissions to 555:
# chmod a+rx /mnt/nifi-dropoff # ll -d /mnt/nifi-dropoff dr-xr-xr-x 1 root russ 4096 May 13 08:21 nifi-dropoff
Later, after mounting, set it to 755 (or whatever permissions you actively want). Then you'll get permission denied if the folder happens not to be mounted.
# chmod u+rwx /mnt/nifi-dropoff # ll -d /mnt/nifi-dropoff drwxr-xr-x 1 root russ 4096 May 13 08:21 nifi-dropoff
How best to enable debug logging in the test framework on ComponentLog?
From Mark Payne, ...
Simple Logger should be used under the hood as the slf4j implementation. So you can set a given logger to DEBUG by using
System.setProperty( "org.slf4j.simpleLogger.log.package-path", "DEBUG" );
Here's an example, for instance, to turn on TRACE-level messages in your JUnit test suite for just your custom-processor code. Also, turn on Apache NiFi code in DEBUG mode.
@BeforeClass
public static void setup()
{
System.setProperty( "org.slf4j.simpleLogger.log.com.mycompany.processor", "TRACE" );
System.setProperty( "org.slf4j.simpleLogger.log.org.apache.nifi", "DEBUG" );
}
Deploying NiFi multi-tenant? How to separate log entries?
Consider a prefix with a name or code identifying the tenant in each process group, including internal ones, and capture the messages (bulletins) with a report task. The bulletins come with the process group name so easily identified by filtering ${NIFI_ROOT}/logs/nifi-app.log.
Check out this article.
The lack of "Version" on the context menu implies that the NiFi Registry has not been added as a client to the NiFi instance. To do so, go to the hamburger menu (upper right), choose Controller Settings, and select the Registry Clients tab. Add registry instance there.
Also ensure the policies on the Registry buckets allow access to you and the server your NiFi is running on.
Updating the authorizers.xml and users.xml is not recommended to be done manually, but rather by managing users and policies in the UI.
The retry processor should only be used if the intent is to do something like "try 5 times, then do something else."
If the intent is rather just to keep trying and also to avoid data loss, you can just route the failure relationship from (whatever processor is your main workhorse) back to itself with nothing in between. This is the typical pattern used in NiFi.
In short: how it works:
There is a database, one of H2, MySql or PostgreSQL, that stores all metadata and knowledge of Registry artifacts, a persistence provider for each versioned flow, extension bundle, etc.
The Git repository is just an implementation of a flow-persistence provide—another place to store a blob. There are also filesystem- and database providers for flow persistence.
When it starts up, if the database is empty and Git is configured, the Registry reads the Git repository to rebuild the database. A trick some administrators use in higher environments like production where the Registry is read-only, is to halt the Registry periodically, delete the database, perform a git pull, and start the Registry again. All is up-to-date at that point.
This error indicates that the flowfile repository failed to update and implies that one of three things happened (Mark Payne). State Management is the problem.
The latest release of NiFi sets up security features enabled by default. What are username and password configured to be?
These are printed in the logs during start-up. To change their defaults, however, ...
$ nifi.sh set-single-user-credentials username password
Why?
Security of freshly installed NiFi instances by default began in Apache NiFi 1.14.0.
Because I just want to get stuff done, test custom processors, etc. I don't write real flows for production use. These back-transformation instructions still worked as of NiFi 1.25.0 to obviate any need for users, groups, certificates, etc.
Edit conf/nifi.properties and make sure that the following are set initially as shown. Note: if you've already run this instance of NiFi, it will be difficult to recover from it and it might be easier to erase and download a virgin instance.
Perform the following edits:
------ new nifi.properties file ------------- ------ changes you'll make to new file --------------- # Site to Site properties nifi.remote.input.host= nifi.remote.input.secure=false (original value: true) nifi.remote.input.socket.port= # web properties nifi.web.http.host=127.0.0.1 nifi.web.http.port=9999 (or whatever port you prefer) ##################################### nifi.web.https.host= (original value: 127.0.0.1) nifi.web.https.port= (original value: 8443) nifi.sensitive.props.key=*** (set by NiFi on first boot or see note below) nifi.sensitive.props.key.protected= nifi.sensitive.props.algorithm=NIFI_PBKDF2_AES_GCM_256 nifi.sensitive.props.provider=BC nifi.sensitive.props.additional.keys= nifi.security.keystore= (original value: ./conf/keystore.p12) nifi.security.keystoreType= (original value: PKCS12) nifi.security.keystorePasswd= nifi.security.keyPasswd= nifi.security.truststore= (original value: ./conf/truststore.p12) nifi.security.truststoreType= (original value: PKCS12) nifi.security.truststorePasswd= nifi.security.user.authorizer= (original value: single-user-authorizer) nifi.security.allow.anonymous.authentication= (original value: false) nifi.security.user.login.identity.provider= (original value: single-user-provider) nifi.security.user.jws.key.rotation.period= (original value: PT1H) nifi.security.ocsp.responder.url= nifi.security.ocsp.responder.certificate=
Upon launching NiFi (bin/nifi.sh start), it will come up as before—no need to authenticate and no need to set the username and password as discussed earlier.
*** If you cleverly wished to replace flow.xml.gz (and flow.json.gz) before launching the new instance for the first time—in order to port your old flow to this new instance, you will find your new NiFi instance broken because the value of property, nifi.sensitive.props.key, is related to the flow.
To avoid the breakage just described, ...
...copy the nifi.sensitive.props.key from nifi.properties in your old NiFi instance to this property in your new instance!
If you've already launched once, you will be replacing a new key with the old one plus, you must remove flow.*.gz from conf, then copy your old, desired flow to the new instance, and, finally, relaunch.
In logs/nifi-app.log are seen recurring timer-driven process thread errors:
o.a.n.c.FlowController Failed to capture component stats for Stats History
java.lang.NullPoinerException: null
at o.a.n.d.SystemDiagnostics.getOpenFileHandles(SystemDiagnostics.java:224)
at o.a.n.c.FlowController.getNodeStatusSnapshow(FlowController.java:3011)
This problem was fixed by Apache NiFi 1.14.0.
Load balancing on a 1.12.1 cluster worked with certain settings, but after a couple of more releases, began failing.
Jens Kofoed says, ...
"In version 1.13.2 nifi.cluster.load.balance.host had to be abandoned in favor of nifi.cluster.load.balance.address and an IP address used instead of a hostname to get it to work. (It turns out that this was someone's typo at the time.)
In version 1.14.0 they have fixed the bug so now it uses the nifi.cluster.load.balance.host property. You must change back again to use this property, but it still doesn't work to use the hostname—only the IP address.However, the change from nifi.cluster.load.balance.address to nifi.cluster.load.balance.host happened in 1.14.0 according to Mark Payne (Apache NiFi Users List, 6 August 2021).
Testing by Mark yields the following experience:
$ nslookup hostname
hostname.lan comes back as the FQDN.
When trying to run the 1.14.0 docker image with the following command, you get SensitivePropertyProtectionException.
David Handermann replies...
NiFi 1.14.0 introduced a change to require nifi.sensitive.props.key in conf/nifi.properties. For new installations of standalone nodes, NiFi will generate a random value automatically, but clustered configurations require setting this value explicitly. This key can be specified using the following environment variable when running in Docker: ${NIFI_SENSITIVE_PROPS_KEY}. The value must be the same on all clustered nodes.
Instance of NiFi 1.14 (single user with password), everything fine until reboot over reboot over the weekend, now unable to restart the container.
NiFi home: /opt/nifi/nifi-current
Recovered flowfile.xml.ga from container thus:
$ sudo docker cp nifi:/opt/nifi/nifi-current/conf/flow.xml.gz .
Cannot seem to use it in another container by mounting it as a volume.
This problem is related to NiFi Migration Required for Blank Sensitive Properties Key.
Once the value of nifi.sensitive.props.key was restored, everything works fine.
Jean-Sébastien Vachon
If a secured NiFi cluster can't send heartbeats between nodes, it may be a problem with certificates.
In setting up a secured cluster with certificates installed on each node, it is important to note that the certificates used by NiFi must be for both server and client. NiFi certificates use the server authorization for NiFi web UI. When other servers connect to it, the client authorization is needed.
Regarding Apache NiFi 1.15.0 — Parameter Context Inheritance, by Joe Gresock, there is a concept of parameter context inheritance in NiFi 1.15.x, but this applies only to a single process group. There is currently no concept of inheritance of parameters through nested process groups. Therefore, a parameter context must be explicily set in each process group, no matter which level, in order for any parameters to be seen.
Prior to NiFi 1.15, no concept of inheritance existed.
What if you were using the InvokeHTTP processor, getting errors, but you didn't know what this processor was doing "behind your back" which is to say what it's passing in the HTTP header?
By default, the logging threshold for NiFi is set to INFO. Raise this to DEBUG to find out. You do this in conf/logback.xml by adding this line:
<logger name="org.apache.nifi.processors.standard.InvokeHTTP" level="DEBUG" />
To continue our example...
Run again and you'll see the effect in logs/nifi-app.log which is to spill out the contents of the header of the request it's issuing.
Perhaps you will discover in this case that this process was sending "useragent" parameter, because you didn't specify anything in InvokeHTTP's Configure Processor → Properties, as an empty value which caused your targeted end-point to complain. Setting a (dynamic) property of "useragent" to "none" in the properties might satisfy your target end-point which will begin to reply with the expected answer.
In this scenario, much is beyond NiFi or the InvokeHTTP processor:
Here's is NiFi's debugging tutorial: https://community.cloudera.com/t5/Community-Articles/NiFi-Debugging-Tutorial/ta-p/246082
The NiFi UI is accessible using client certificates. The username in NiFi must match the common name provided in the client certificate.
Memory depends on flow needs. Usually 8Gb for the JVM heap is more than enough for medium to large flows. 8Gb of heap would mean at least 16Gb of physical memory underneath.
To set JVM memory for NiFi, ...
# JVM memory settings java.arg.2=-Xms512m java.arg.3=-Xmx512m
java.arg.3=-Xmx8192m
When NiFi goes under high load the web UI becomes unresponsive until the load comes down. Is there a way to see what's going on (processor status summary, queued count, active thread count) when the UI is unresponsive?
The logs show no errors and the various repositories are all mounted to separate volumes so none have run out of space. Monitoring shows bursts of CPU usage, but memory use is lower than normal.
The logs show that the StandardProcessScheduler stops processors followed by restarting them, but no log statements related to the UI being ready to serve appear. It does this about once per hour. Based on log activity and databases, the flow is slowly processing.
How to see what's going on when the web UI is not responding? Also, it appears that NiFi keeps restarting itself. An out-of-memory killer is doing this?
Then the UI isn't responsive, it's good to have a snapshot of:
It might be worth setting (disabled by default at least beginning in NiFi 1.15:
nifi.monitor.long.running.task.schedule=9999
One of/or number of remedies like
...can help resulting in seeing the UI come alive and watching files go through again.
NiFi uses the Jython engine, rather than pure Python. Although it's therefore impossible to use native (C-Python) libraries like Pandas, Java classes can be imported and used. This means that Jython can call Java methods such as outputstream.write() and session.transfer().
A good place to start to understand the NiFi API is the Developer Guide. This covers well the concepts you may run into in any script.
Begin with the ProcessSession API. You can call methods on the session, such as writing to a flow file using a StreamCallback within which you can see the process method. For ProcessSession, you can also see transfer() and putAttribute() which are very often used in scripts.
Having set up the Apache NiFi server with client certificates for the admin user as well as policies, created some group(s) and users using the NiFi UI, how do these users authenticate to NiFi? Must certificates be generated for each? How is this done?
Brian Bende answers:
Of two ConsumeKafka processors (NiFi 1.16.1), the first uses Topic Name Format of "names." The second uses Topic Name Format of "pattern." The names format is able to sync with Kafka relatively quickly and begins receiving messages within just a couple seconds. However, the pattern format takes significantly longer to start receiving messages.
Diving into the logs, it appears the issue is that the consumer does not yet have the proper offset, so it cannot begin pulling messages. Eventually, this is seen in the log:
INFO [Timer-Driven Process Thread-6] o.a.k.c.c.internals.ConsumerCoordinator \
Setting offset for partition test.topic.1-0 to the committed offset \
FetchPosition{offset=18, offsetEpoch=Optional.empty, \
currentLeader=LeaderAndEpoch{leader=Optional[kafka1:12091 (id: 1 rack: r1)], epoch=0}}
INFO [Timer-Driven Process Thread-6] o.a.k.c.c.internals.ConsumerCoordinator \
Setting offset for partition test.topic.1-1 to the committed offset \
FetchPosition{offset=13, offsetEpoch=Optional.empty, \
currentLeader=LeaderAndEpoch{leader=Optional[kafka2:12092 (id: 2 rack: r2)], epoch=0}}
Very soon after, messages started arriving.
Is this lag an issue with the Kafka server? Or can the server be queried/forced to establish the offset more quickly in cases when it is not yet known?
Reducing the yield time seems to speed the process up a bit. The implication is that the offset is established in relation to the number of polls attempted. But, with a wide range of lag times seen, it's unclear that there is a direct relationship.
Knowles Atchison replies:
When a consumer first connects to a Kafka cluster, there is a metadata handshake that transmits things like consumer group assignments and offsets. In application code, the first poll establishes this information and does not actually retrieve messages, depending on timeout used. Consumers have a configuration setting auto.offset.reset that specifies what to do in the event there is no offset or the current offset does not exist. Kafka will then rewind to the beginning for the "earliest" to tail the end with "latest" (the default).
With the default latest setting, after that first poll, the consumer may be waiting if new messages are not constantly coming in. This may also be compounded with how long the processor is waiting between calling poll() itself.
In client applications, to get the consumer group assigned and rewound as quickly as possible, do this:
consumer.subscribe( Collections.singletonList(testTopic ) ); // "fake" poll to get assigned to consumer group, auto offset will kick in to earliest consumer.poll( Duration.ofMillis( 0 ) ); ConsumerRecords< String, String > records = consumer.poll( Duration.ofMillis( 5000 ) ); for( ConsumerRecord< String, String > record : records ) logger.info( "Message received: " + record.toString() );
See Kafka Documentation here.
Note that property, metadata.max.age.ms, doesn't exist in the NiFi processor, however, any property dynamically created in ConsumeKafka will be passed down to the underlying Kafka (consumer in this case) client as if set there.
Also, when a new topic is created that matches the pattern configured in ConsumeKafka, it will get picked up the next time synchronization occurs.
Some observations I found and conclusions I reached researching Standard[Restricted]SSLContextService. I don't completely understand what each of these means.
Here's a development script to use to update one or more active NiFi environments:
#!/bin/bash
# Update the right-version NiFi with our NAR.
if [ "$1" = "--help" ]; then
echo "Usage: $0 <NiFi version>"
exit 0
fi
CWD=`pwd`
SANDBOXES="/home/russ/sandboxes"
PIPELINE_NAR="acme-pipeline/nar/target/acme-pipeline-*.nar"
NIFI_DEV="/home/russ/dev/nifi"
VERSION="${1:-}"
NIFI_PATH="${NIFI_DEV}/nifi-${VERSION}/custom-lib"
PIPELINE_PATH="${SANDBOXES}/${PIPELINE_NAR}"
CWD=`basename ${CWD}`
if [ "$CWD" = "acme-pipeline" ]; then
echo "Updating NiFi ${VERSION} with new NAR from ${PIPELINE_PATH}..."
cp ${PIPELINE_PATH} ${NIFI_PATH}
else
echo "Not in suitable place from which to update anything."
fi
# vim: set tabstop=2 shiftwidth=2 noexpandtab:
Here's a development script to use to bounce one or more active NiFi environments:
#!/bin/sh
# Usage: bounce-nifi.sh [-z] <version> [ <versions> ]
# version may indicate nifi-registry.
# -z causes logs to be restarted
if [ "$1" = "--help" ]; then
echo "Usage: $0 [-z] <NiFi version> [ <more NiFi versions> ]"
echo "version may indicate NiFi or NiFi Registry (or both)"
echo "Options: z zaps all logfiles"
exit 0
fi
TRUE=1
FALSE=0
DEV_PATH="/home/russ/dev/nifi"
ZAP_LOG=$FALSE
zap="${1:-}"
if [ -n "$zap" ]; then
if [ "$zap" = "-z" ]; then
ZAP_LOG=$TRUE
shift
fi
fi
if [ $ZAP_LOG -eq $TRUE ]; then
echo "Zapping all logs..."
fi
VERSIONS="$*"
for v in $VERSIONS; do
#echo "Looking for $version candidate $v..."
candidate="$DEV_PATH/nifi-$v/bin"
#echo "Looking for Registry $version candidate $v..."
registry_candidate="$DEV_PATH/nifi-registry-$v/bin"
#echo "Trying candidate: $candidate..."
if [ -d "$candidate" ]; then
instances="$instances $candidate"
fi
if [ -d "$registry_candidate" ]; then
instances="$instances $registry_candidate"
fi
done
echo "Instance(s) found: $instances"
for instance in $instances ; do
echo "Bouncing instance $instance..."
if [ $ZAP_LOG -eq $TRUE ]; then
cd $instance && rm -f ../logs/*.log
fi
if echo "$instance" | grep -q "registry"; then
cd $instance && ./nifi-registry.sh stop && ./nifi-registry.sh start
else
cd $instance && ./nifi.sh stop && ./nifi.sh start
fi
done
# vim: set tabstop=2 shiftwidth=2 noexpandtab:
...and backward compatibility.
If you have promoted your code defining a PropertyDescriptor's use of the NiFi Expression Language from
... .expressionLanguageSupported( true ) .build();
...to something like:
... .expressionLanguageScope( ExpressionLanguageScope.FLOWFILE_ATTRIBUTES ) .build();
...then find that you must still load your NAR under former versions of NiFi, your NAR will not in fact load. There was no scope prior to version 1.7.0 (I think this is when ExpressionLanguageScope was added), but, for backward-compatibility, the original coding (with argument true or false) is supported.
However, that backward compatibility will not save you from trouble using the test framework, which will crash down inside the framework, and you must add, to every property accommodating NiFi Expression Language support, the following (in your test code shortly after defining your test runner). And, you will not be able to consume ExpressionLanguageScope in your backward-compatible code:
private CustomProcessor processor = new CustomProcessor(); private TestRunner runner = TestRunners.newTestRunner( processor ); runner.setValidateExpressionUsage( false );
I do work that supports customers running back as far as NiFi 1.1.2. Backward compatibility is of the utmost importance to me. I cannot make use of scope-based calls.
Caused by: org.apache.nifi.processor.exception.FlowFileHandlingException:
FlowFile[0,276675224886203.mockFlowFile,1673B] \
is not the most recent version of this flow file within this session
—a common problem arising from forgetful coding is to fail to get the most recent version of the flowfile when you modify it—most commonly when you put a new attribute:
session.putAllAttributes( flowfile, errorAttributes );
Did you forget that this put operation modifies the flowfile? To get the latest version, remember to do this:
flowfile = session.putAllAttributes( flowfile, errorAttributes );
If you use Java's LinkedHashSet (in place of ordinary HashSet), you will ensure that the processor Usage documentation retains the order you created them in. Let's say you have success and three different failure arcs created and you want them in a particular order that makes sense to you and your down-streamers, ...
...
private Set< Relationship > relationships;
@Override public Set< Relationship > getRelationships() { return relationships; }
@Override public void init( final ProcessorInitializationContext context )
{
...
Set< Relationship > relationships = new LinkedHashSet<>();
relationships.add( SUCCESS );
relationships.add( FAILURE_1 );
relationships.add( FAILURE_2 );
relationships.add( FAILURE_3 );
this.relationships = Collections.unmodifiableSet( relationships );
}
}
Matt Burgess says the biggest problem with JSON columns across the board is that
We are only interested in the overall datatype such as String since NiFi records can be in any supported format. These are handled by setting the JSON column to type java.sql.OTHER (as does PostgreSQL) and they are willing to accept the value as a String (see NIFI-5901), and we put in code to handle it as such (see NIFI-5845).
For NiFi it's been more of an ad hoc type of support where maybe if the SQL type is custom and unique we can handle such things (like sql_variant in MSSQL via NIFI-5819), but due to the nature of the custom type it's difficult to handle in any sort of consistent way.
When I have input processors, such as GetFile or GenerateFlowFile, I don't want them performing much—just maybe let one flowfile squeak through. This is because I'm mostly concerned with extraction, transformation and loading (ETL).
As soon as I run (turn on the processor), the most I'll get out of it is one squirt, the squirt I'm interested in observing or debugging.
When the processor is finished running, it will wait 60 seconds before even thinking about running again.
What this buys me is that I can easily start the processor, but I don't have to micromanage how quickly or surely I stop it (turn it off). I have many seconds to accomplish that before, sometimes annoyingly or even catastrophically, another squirt of data is introduced into the pipeline.
For GetFile, I make certain to configure it not to remove source files after it sends them since I don't want my test fodder to disappear.
Under the Properties tab, set Keep Source File to true. This is not the default.
Also, set Batch Size to 1 to reduce the number of data files to a single one. This holds for GenerateFlowFile as well.
Deploying several NiFi containers as part of a service. The problem may be more Java/Docker/VMWare than NiFi. Recently upgraded a small system in Azure to 1.19. using the "official" Docker container—worked just fine. The host was an Azure VM running an older CentOS 7 image. There were no issues.
On a current install, however, the same Docker image are hosts (3 of them) with 8 core/64G. Errors are like:
Jan 27 16:32:36 dstsc01 cust-sts|2181237bc92f[1788]: replacing target file /opt/nifi/nifi-current/conf/bootstrap.conf
.
.
.
Command Line: -Xms48m -Xmx48m \
-Dorg.apache.nifi.bootstrap.config.log.dir=/opt/nifi/nifi-current/logs \
-Dorg.apache.nifi.bootstrap.config.pid.dir=/opt/nifi/nifi-current/run \
-Dorg.apache.nifi.bootstrap.config.file=/opt/nifi/nifi-current/conf/bootstrap.conf org.apache.nifi.bootstrap.RunNiFi run
Tried setting the bootstrap memory Xmx/Xms to different amounts from 2G to 32G, but it made no difference with the memory error above. The error appears to be part of the bootstrap, so not even getting to the point where the memory configuration would make any difference.
Response...
Tried an earlier version of nifi in the same environment? Does the image for NiFi 1.18.0 boot successfully, for example?
The reason to check this is mainly that the Apache NiFi convenience Docker image switched from Java 8 to Java 11 for version 1.19.0. The way in which memory is allocated to the JVM within a Docker container changed between Java 8 and 11, so it might be worth checking to see whether an earlier version works.
Is the VMWare environment 64- or 32bit. That may also affect how the JVM allocates memory (based on a brief search). See Compressed O[rdinary]O[bject]P[ointers] in the JVM
Solution...
Docker version was 18.x.x. Upgrading to Docker 20.10.13 resolved the issue.
There a few caveats and issues to be discovered going down this road.
Stand-alone NiFi in a container works pretty much as one would expect. Care must be taken where NiFi configuration directories are mounted, that is, the data repositories:
...and these subdirectories:
All of these are actively (constantly) written to by NiFi and it's good to have them exported as bind mounts external to the container.
The files...
...should be bind mounts also or live dataflow configuration changes will be lost.
Any change to the NiFi canvas gets written to these files which means a copy of them must be kept outside of the container or the changes will die with the container's demise.
These are potentially other files in the conf folder to keep around, potentially certificates to be shipped with the specific container, and still others. Unfortunately, Apache NiFi doesn't organize the location of all this to a single point by default, so a lot of different path must be reconfigured or bind-mounted in consequence. Presumably this chaos will be solved in NiFi 2.0.
NiFi clustering with a Dockerized environment is less desirable.
The primary problem is that the definition of cluster nodes is mostly hard-coded into...
In a containerized environment, the ability to bring nodes up and take them down (with dynamic IP/network configuration) is needed especially in container orchestration frameworks like Kubernetes.
There have been a lot of experiments and possibly even some reasonable solutions come out to help with containerized clusters, but generally a lot of knuckle-cracking will be required to get it to work.
If content with a mostly statically defined, non-elastic cluster configuration, then a clustered NiFi on Docker is possible. Obviously, a single-node Docker container is much easier to manage and many of the caveats expressed in these notes don't apply or aren't that hard to mitigate.
As an option, with stand-alone deployments, individual NiFi node instances should be fronted with a load balancer.
This may be a poor-man's approach to load distribution, but it works reasonably well even on large volume flows. If the data source can deliver to a load balancer, that balancer round-robins (etc.) to the underlying stand-alone nodes.
In a container orchestration environment, Kubernetes (or other) can spin up and down containerized nodes to handle demand managing a load balancer configuration as those nodes are coming up. This is all possible, but requires effort.
Doing anything with multiple stand-alone nodes requires propagating changes from one NiFi canvas to all nodes manually (containerized or not). This is a huge pain and not really scalable. So the load balancer approach is only good if dataflow configurations are very static and don't change in day-to-day operations.
Another acute issue with containerized NiFi is what to do with the flow configuration itself.
On the one hand, there is the temptation to "burn" the flow configuration into the Docker image (conf/flow.xml.gz and conf/flow.json.gz). That configuration would thereby be included as part of the image itself. (Yeah!) This would enable NiFi to come up with a fully configured set of processors ready to accept connections. But...
...part of the fun with and utility of NiFi is being able to make dataflow and processor configuration changes on the fly as needed based on operational conditions. For example, maybe temporarily stop data moving to one location to have it rerouted to another. This "live" and dynamic way to manage NiFi is a powerful feature, but it kind of goes against the grain of containerized or a static deployment approach. New nodes coming on line would not easily get the latest configuration changes that DevOps staff has added recently.
Then again, the NiFi Registry can somewhat help in this last instance.
After 3 days NiFi starts a process named myssqlTcp that takes over 500% CPU utilization when running htop. It appears related to NiFi. It's deployed from a recent Docker image from DockerHub (PULL apache/nifi).
This isn't typical of NiFi. What appears to be the problem is a cryptominer. It results from connecting the (NiFi) server to the Internet without authentication or using a weak password. Publicly accessible NiFi servers are quickly exploited to run ExecuteProcess and deploy garbage like a minor.
This is a malicious process as indicated by the name matching nothing in NiFi or anything you recognize and the CPU load is high. If killed, there will be a persistence mechanism that restarts it.
The solution is to wipe NiFi, in this case the Docker image deployment. Redeploy an instance correctly and safely.
Your process group is empty, but, attempting to delete it from the canvas, you get:
Cannot delete Process Group because it contains 1 Templates. The Templates must be deleted first.
This occurs because, while inside that process group, you imported a template. You must first enter the group, go to the Hamburger menu, click Templates, then remove the template you added when editing that group.
Note that, unless you know the process group id that owns the template(s), it's unclear which template in the list is associated with the process group you're trying to remove.
Removing a template doesn't remove the flow it gave you when you imported (Uploaded Template) it. It just means that you'll have to import/upload it again if you need it.
Templates are associated with the process group (including the root) active at the time you uploaded them in order to protect them using the same security policies in effect in that process group. View Templates is still from the global (hamburger) menu as late as Apache NiFi 1.19.1.
My solution to lessening the confusion is to import (that is, Upload Templates at the root level, then consume them down inside process groups. Unfortunately, I don't have a lot of experience creating and observing complex flows to understand the exact behavior.
See Can't delete process group—because it "contains 1 Templates".
At the user interface level, Apache NiFi calls logging "bulletins."
When a processor (including custom processors) logs anything as DEBUG, INFO, WARN, ERROR, the log message is collected and displayed on NiFi's very convenient Bulletin Board which is reached via the General (hamburger) menu's submenu, Bulletin Board.
If the logged message is done in levels WARN or ERROR, a red smear will be placed in decoration at the top-right of the processor box )in the UI). Hovering over it will display the log messages (i.e.: bulletins) for some 5 minutes after the event occurs.
Logging in a custom processor (standard, Apache processors are all uniform in this) must be done using abstract class AbstractProcessor's
ComponentLog logger = getLogger();
(Formerly, this was done with getComponentLogger(), but that practice disappeared between 0.7.4 and 1.0.0 becoming a code-compilation disparity. I was there and suffered this, having to "port" many processors.)
Typically, one defines the relationship arcs in a custom processor using HashSet thus:
@Override
public void init( final ProcessorInitializationContext context )
{
// create static properties and relationships...
...
Set< Relationship > relationships = new HashSet<>();
relationships.add( SUCCESS );
relationships.add( FAILURE );
relationships.add( FAILURE_NO_MPID );
relationships.add( FAILURE_INTERNAL_ERROR );
this.relationships = Collections.unmodifiableSet( relationships );
}
However, this may result in them being documented when View Usage is chosen in the NiFi UI in a random, potentially illogical order. To ensure this doesn't happen, use LinkedHashSet instead:
...
Set< Relationship > relationships = new LinkedHashSet<>();
...
An uncommon problem post Apache NiFi 1.0. This occurs when the custom processor was linked with an old nifi-nar-maven-plugin that doesn't set a version on the processor. The solution is to update the Maven plug-in (very seriously).
Meanwhile, in the left pane (list of processors), if you scroll down to the one you're looking for and select it, you'll see the View Usage documentation.
Using Apache NiFi and Registry 1.21.0 for a project. Both are secured against an FQDN instead of localhost.
When NiFi is restarted, there are no issues for a while. Suddenly a question mark appears against the process group:
logs/nifi-app.log displays:
2023-05-15 03:12:42,437 ERROR [Timer-Driven Process Thread-6] o.a.nifi.groups.StandardProcessGroup \
Failed to synchronize StandardProcessGroup[identifier=c08db5d3-0187-1000-47d1-021d3fe4547b,name=Ingest Stats] \
with Flow Registry because could not determine the most recent version of the Flow in the Flow Registry
org.apache.nifi.registry.flow.FlowRegistryException: Error retrieving flow: Unknown user with identity 'anonymous'. Contact the system administrator.
at org.apache.nifi.registry.flow.NifiRegistryFlowRegistryClient.getFlow(NifiRegistryFlowRegistryClient.java:233)
...
Caused by: org.apache.nifi.registry.client.NiFiRegistryException: Error retrieving flow: Unknown user with identity 'anonymous'. Contact the system administrator.
at org.apache.nifi.registry.client.impl.AbstractJerseyClient.executeAction(AbstractJerseyClient.java:117)
...
... 12 common frames omitted
Caused by: javax.ws.rs.NotAuthorizedException: HTTP 401 Unauthorized
at org.glassfish.jersey.client.JerseyInvocation.convertToException(JerseyInvocation.java:942)
...
... 14 common frames omitted
NiFi is, manifestly, secured and configured to authenticate against LDAP with
... nifi.security.allow.anonymous.authentication=false ...
Why is NiFi unable to send user credentials to the Registry?
Bryan Bende responds that most likely the server certificate created for the NiFi instance does not offer clientAuth which is required for a NiFi cluster and also for communicating with the Registry, a two-way TLS with proxied entity identity.
This includes the keystore itself. If keytool is used to list the keystore.jks that NiFi is using, the extended key usage part is required including both serverAuth and clientAuth. If it it has only serverAuth, then it would likely produce the issue seen here. If that is the case the keystore must be re-generated.
...(property name) is not a supported property of has no Validator associated with it."
The above is an AssertionError coming back from NiFi code. Obviously, check all the properties (well, specifically the one named in the error message) to ensure you're validating, but another face-plant realization is that the key is "is not a supported property" in the sense that you may have stupidly overlooked putting it into List< PropertyDescriptor > properties at the initialization of your (custom) processor.
I'm trying to build NiFi 1.13.2 by hand, after downloading the source zip, exploding it and successfully building the Docker image to include Java 11 instead of Java 1.8. I am only doing this to NiFi 1.13.2 for my purposes. Therefore, the following explanation applies only to that version.
Should you wish to build Apache NiFi by hand, note that org.codehaus.groovy.groovy-eclipse-batch, version 2.5.4-01, no longer exists on Maven Central. However, notice that, as of today at least, version 2.5.6 does exist.
So, I changed the following in the root pom.xml:
<properties>
<maven.compiler.source>11</maven.compiler.source> (used to be 1.8)
<maven.compiler.target>11</maven.compiler.target> (used to be 1.8)
...
<nifi.groovy.version>2.5.6</nifi.groovy.version> (used to be 2.5.4)
...
Also, as I don't care to run tests as I build, I turned them off. I used this command at the root:
$ mvn clean -DskipTests=true package
Also, I found that com.fluenda:ParCEFone:jar:1.2.6 no longer exists (as referred to by nifi-nar-bundles/nifi-standard-bundle/pom.xml) and I changed it to 1.2.8.
In nifi-nar-bundles/nifi-splunk-bundle/pom.xml:
<url>https://splunk.artifactoryonline.com/artifactory/ext-releases-local</url>
Set< String > keys = new HashSet<>( 3 ); keys.add( "a" ); keys.add( "b" ); keys.add( "c" ); flowfile = session.removeAllAttributes( flowfile, keys );
There's also simply this call to remove one attribute:
flowfile = session.removeAttribute( flowfile, "a" );
I have a custom processor that splits out individual FHIR resources (Patients, Observations, Encounters, etc.) from a great Bundle flowfiles. So, for a given flowfile, it's split into hundreds of smaller ones.
When I do this, I leave the existing NiFi attributes as they were on the original flowfile.
As I contemplate the uuid attribute, it occurs to me that I should find out what its significance is for provenance and other potential debugging/tracing concerns. I never really look at it, but, if there were some kind of melt-down in a production environment, would I care that it multiplied across hundreds of flowfiles besided the original one?
Also attributes filename and path remain unchanged.
I do garnish each flowfile with many pointed/significant new attributes like resource.type that are my own. In my processing, I don't care about NiFi's original attributes, but should I?
Matt Burgess recommends only passing on those attributes that will be used down-stream (unless there's an original relationship that should maintain the original state with respect to provenance).
Note that both session.create() and session.clone() create a new uuid for the new flowfile they return.
uuid cannot be modified; it's automatically generated. An attempt to change it via session.putAttribute() with it as the key will be ignored. (Mark Payne)
uuid figures prominently in the display of provenence, see Apache NiFi - Data Provenance.
A conversation around Eric Secules' question.
Eric Secules:
I have NiFi started with -Xms and -Xmx set to 4Gb and Docker memory resource limits of 8Gb on the container for a small test environment. And it gets killed by K8s for consuming too much memory after the tests run for a while. My workload is automated tests where each test puts a flow (average 70 processors) on the canvas, runs files through, and removes the flow when the test is done. About four of these tests run in parallel. We are only testing flow functionality so the flows only deal with 10s of flowfiles each.
I am still on NiFi 1.14.0 and I would like to know what other things in nifi contribute to memory use besides flowfiles in flight. Also is it normal that I see my containers using much more memory than I allotted to the JVM?
From Joe Witt:
Try using 2Gb for the heap and seeing that helps. I also believe there are specific pod settings youll want to use to avoid it getting nuked by K8s.
This blog may give you great things to consider:
What everyone should know about Kubernetes memory limits, OOMKilled pods
and pizza parties
From David Handermann:
It is important to note that Java process memory usage consists of multiple factors beyond the maximum heap size. Kubernetes limits are based on total memory usage, so it is essential to account for all Java memory elements when specifying Kubernetes memory limits.
The following article has a helpful summary of Java Virtual Machine memory
usage:
How the JVM uses and allocates memory
The formula for memory usage is helpful:
JVM memory = Heap memory + Metaspace + CodeCache + ( ThreadStackSize * Number of Threads ) + DirectByteBuffers + JVM-native
Based on that formula, several key factors include the total number of threads, and the size of direct byte buffers.
Specifically, it is important to highlight that the default direct byte buffer limit is equal to the maximum heap size. This means that unless the size of direct memory is configured for the JVM, using a custom argument in conf/bootstrap.conf, the maximum heap size should be something less than half of Kubernetes memory limits.
All of these factors will be different based on the particular processors configured, and the specific configuration parameters selected. Some processors use direct byte buffers, others do not, so it depends on the supporting libraries used.
"Custom" because, if you're a developer, you're likely making changes without bumping the version each time in the observe-detect-edit cycle. The browser is unable to detect the presence of the changes and refuses to update its cache.
The solution would be to force the browser to update its cache. Unfortunately, View usage engages an iframe from which there is never a vantage point to hold down the Shift key while invoking Reload. It's not even possible to effect the change by wiping the browser cache by hand.
However, additionalDetails.html does not suffer from this problem.
The values of properties in the flow, including sensitive properties, can be parameterized using Parameters. Parameters are created and configured within the NiFi UI. Any property can be configured to reference a Parameter with the following conditions:
Parameters are always stored in NiFi itself, encrypted in flow.xml/flow.json. Parameter providers are a way to easily import parameters and values from an external source like Vault and other various secret stores, but they are still ultimately brought into NiFi and stored locally.
NiFi Registry is not a parameter provider. When a flow is saved to NiFi registry, it contains a snapshot of what the parameter contexts were at the time the flow version is being saved (minus sensitive values). On import of this flow from registry to another NiFi instance, it will attempt to create/update parameter contexts based on the snapshot in the flow being imported, and any sensitive values would need to be populated after the import.
The only possible combination of .required( false ) and .addValidator(). Otherwise, you get an error from the UI when you haven't configured the optional property value. Why have I never noticed this until now?
public static final PropertyDescriptor X = new PropertyDescriptor.Builder()
.name( "x" )
.displayName( "x" )
.required( false )
.addValidator( Validator.VALID )
.addValidator( StandardValidators.NON_BLANK_VALIDATOR )
.description( "Does x..." )
.build();
In Apache NiFi, component is defined as a processor, controller service, reporting task or parameter provider. In short, a component is one of these entities that is added, connected or configured on the NiFi UI canvas.
Events occur in coded methods that are annotated using the following:
It is my understanding (I mostly write custom processors) that these annotations imply order and correspond to UI actions:
There are generally 4 things that cause the flowfile repository to grow huge.
The situations above can be identified by looking for errors in the logs.
For this one, you need to understand whether or not you're creating huge flowfile attributes. Generally, attributes should be very small—100-200 characters or (a lot) less, ideally. It’s possible that you have a flow that creates huge attributes but the flow is only running on the primary node, and node 2 is your primary node, which would cause this to occur only on this node.
Doing...
select * from table ... ;
...producing error like:
2014-03-19 12:58:37,683 ERROR 'Load-Balanced Client Thread-6] \
org.apache.nifi.engine.FlowEngine Uncaught Exception in Runnable task \
java.lang.OutOfMemoryError: Java heap space
This means request sizes must be limited, specifically (for this processor), Fetch Size. Limit it to something like 1000. When set to the default 0, PostgreSQL fetches the entire ResultSet into memory.
$ cd /opt/nifi/current-nifi/conf # go to NiFi's configuration subdirectory $ cp flow.xml.gz /tmp # copy the (XML) flowfile tarball to /tmp $ cd /tmp # go to /tmp $ gunzip flow.xml.gz # explode the tarball $ cat flow.xml | tidy -xml -iq | less -R # run tidy to display it
$ cd /opt/nifi/current-nifi/conf # go to NiFi's configuration subdirectory $ cp flow.json.gz /tmp # copy the (JSON) flowfile tarball to /tmp $ cd /tmp # go to /tmp $ gunzip flow.json.gz # explode the tarball $ jq -C "." flow.json | less -R # run jq to display it
In NiFi v1.x, right click on the process group, download the flow definition to get the JSON file (NiFi v2 doesn't use XML). In NiFi v2, drag and drop a process group on the canvas, click the upload icon on the right of the name input, find and select the downloaded JSON file.
(This is an update of ...remote debugging of NiFi processors using IntelliJ IDEA written on Wednesday, 23 March 2016. See Update of remote debugging of NiFi processors using IntelliJ IDEA.)
If I have a NiFi cluster and a processor that is scheduled to run on all nodes, a queue for said processor basically represents only what's moving on that node, right? And since the configured back-pressure thresholds are also per node, it could be the case that a single node is slower and reaches the threshold while the others run normally. If the processor is only back-pressured in one node, does that also halt scheduling for the same processor in the other nodes?
Pierre Villard responds,
Back-pressure is a node-level concept. If there is back-pressure on one node, it does not impact other nodes. So the statement, "it could be that 1 node is slower and reaches the threshold while the others run normally," is correct.
The NiFi System Administrator's Guide says that NiFi requires Java 8 or 11, but Java 17 was added in version 1.16.0. Generally, NiFi 1.x is built atop Java 8, but validated to run on Java 8, 11 and 17. NiFi 2.x begin Java 21 for its lowest assumption of version support.
We have records going through and failing in HAPI FHIR's parser yet, when we send the same records back through (retrying them), they do not fail. When singly threaded, the parser (used in my custom processor) they do not ever fail.
If I click in IDEA into
...I see a comment at the top of the Java source for this class:
A parser [...] can be used to convert between HAPI FHIR model/structure objects and their respective wire formats, in either XML or JSON. Thread safety: Parsers are not guaranteed to be thread safe. Create a new parser instance for every thread or every message being parsed/encoded.
I had never seen this note and so have been coding processors to allocate a parser when scheduled, keep it for all work (passing flowfiles) while up, then toss it when unscheduled. This was a mistake found only when the system is under heavy load (with multiple threads consciously configured).
It appears that FHIR context is thread safe (and somewhat heavy to instantiate) as well as (I hope) the FHIRPath engine because the latter is insancely expensive in time to crank up.
Wrestling with flow.xml.gz and flow.json.gz and a canvas that will not start up because I broke it by renaming a custom processor, I discovered that it's possible to inspect logs/nifi-app.log for what's wrong (a broken connection), remove the connection from flow.xml, then attempt to restart. This had to be done 3 times (trial and error) because that processor had 3 relationship arcs:
~/dev/nifi/1.27.0/bin $ ./nifi.sh stop ~/dev/nifi/1.27.0/conf $ rm flow.json.gz ~/dev/nifi/1.27.0/conf $ gunzip flow.xml.gz (find the connection by the id given in the log file; remove <connection> ... </connection>:) ~/dev/nifi/1.27.0/conf $ gvim flow.xml ~/dev/nifi/1.27.0/conf $ gzip -c flow.xml.gz > flow.xml.gz (use my macro for restarting:) ~/dev/nifi/1.27.0/logs $ bounce-nifi.sh -z 1.27.0 && tail -f nifi-app.log keep flow.xml, but lather, rinse and repeat the other steps...
And, yes, the above works fine without specific attention to the JSON flow.
Do this in the systemd configuration file; on Ubuntu, Mint, etc., this is something like /etc/systemd/system/nifi.service. It contains:
[Service] Environment=NIFI_HOME=/opt/nifi
As I'm way past running Java 8 or 11 these days and older versions of NiFi won't run atop JDK 21, here's how I get around that:
russ@tirion ~/dev/nifi/nifi-1.1.2/bin $ export JAVA_HOME=~/dev/jdk11.0.25+9 russ@tirion ~/dev/nifi/nifi-1.1.2/bin $ nifi.sh start
Note in passing that the way $JAVA_HOME is changed for an instance of NiFi is to go to ${NIFI_HOME}/conf/bootstrap.conf and change configure to the desired JDK thus:
... # Java command to use when running NiFi java=/home/russ/dev/jdk-21.0.4+7 ...
The above works for NiFi when run as a service too.
Should not a file in my IntelliJ IDEA project on the path project/src/test/resources/logback-test.xml,
containing:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-4relative [%thread] %-5level %logger{5}.%method:%line -
%message%n</pattern>
</encoder>
</appender>
<logger name="com.windofkeltia.processor" level="TRACE" additivity="false">
<appender-ref ref="CONSOLE" />
</logger>
<root level="TRACE">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
show me ComponentLog statements inside onTrigger() such as?
getLogger().debug( "Log statement stuff..." );
I'm debugging on Apache NiFi 1.28.1. My JUnit set-up, which works, but just doesn't yield to my non-INFO logging requests, looks as you'd expect:
private ProcessorName processor;
private TestRunner runner;
@Test
public void test()
{
runner = TestRunners.newTestRunner( processor = new ProcessorName() );
runner.setValidateExpressionUsage( false );
... (etc.)
runner.enqueue( new ByteArrayInputStream( CONTENT.getBytes() ) );
runner.run( 1 );
...
}
As I say, everything is working impeccably (JUnit, my processor, everything), I just can't get logging tailored to show me TRACE, DEBUG, etc. in JUnit tests run inside IntelliJ IDEA without changing them to INFO. I have also tried modifying the "same" file on the path project/src/main/resources/logback.xml.
Mark Payne replies, ...
Generally, no. logback is not typically included on the class path for processors but instead is inherited at the root level of NiFi's class loader hierarchy. For processors, you should generally add a test dependency on slf4j-simple [in pom.xml]. You can then configure that via a file in your src/test/resources directory, or you can configure it using System properties directly within the test class.
Customers/users of a NiFi flow can (still) modify ${NIFI_HOME}/conf/logback.xml to tailor the NiFi ComponentLog to react to DEBUG, TRACE, etc.:
getLogger().[debug|trace|etc.]( "Log statement stuff..." );
but that isn't a workable solution for JUnit testing when modifying NiFi's component logger is needed.
where not using NiFi's component logger, for example, this code:
package com.windofkeltia.code;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Foo
{
private static final Logger logger = LoggerFactory.getLogger( Foo.class );
...
public void bar()
{
logger.trace( "Hi, I'm tracing bar() here..." );
...
}
...
}
...the use of a line in src/test/resources/logback-test.xml like this one is effective:
<logger name="com.windofkeltia.code" level="TRACE" additivity="false"> <appender-ref ref="CONSOLE" /> </logger>
Note that NiFi 2.x and above require Java 21 as the minimum version, which is the reason for the UnsupportedClassVersionError shown by Java 17.
One way to reduce the bottleneck in a processor is to increase the number of threads (see Concurrent Tasks in the processor's SCHEDULING configuration tab).
Another way is the let the processor run longer, say 1 second. That will tend to empty out a queue that's filled if the processor otherwise isn't having to work very hard to perform its processing.
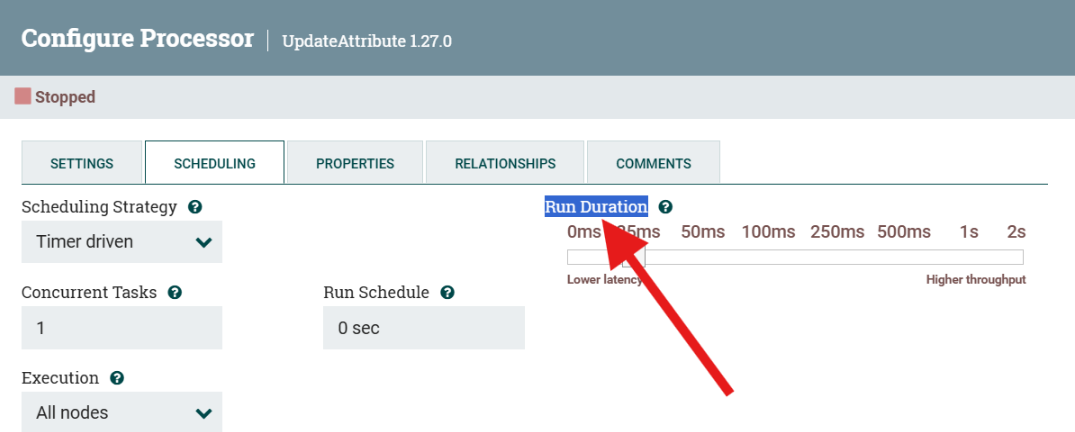
To add run duration to a custom processor, your processor must be thread-safe and you must key off of the @SupportsBatching annotation plus track execution time.
@SupportsBatching
public class CustomProcessor extends AbstractProcessor
{
@Override
public void onTrigger( final ProcessContext context, final ProcessSession session ) throws ProcessException
{
FlowFile flowfile = session.get();
if( isNull( flowfile ) )
return;
long start = System.currentTimeMillis();
...
long stop = System.currentTimeMillis();
long duration = stop - start;
// this adds run duration as a flowfile attribute--you don't need to do this if not important to you
flowfile = session.setAttribute( "run.duration", String.valueOf( duration ));
session.transfer( flowfile, SUCCESS );
}
This note is not well developed; I still need to work up an example and do some research. https://help.hcl-software.com/commerce/9.1.0/search/tasks/t_createcustomnifi.html
[Unit] Description=Apache Nifi After=network.target [Service] Type=forking ExecStart=/opt/nifi/bin/nifi.sh start [Install] WantedBy=multi-user.target
Injecting annotation @SupportsBatching causes the UI to display a Run Duration slider in the UI. The effect is very simple.
It's important, when resorting to this annotation (and behavior) that the processor code be also @SideEffectFree which I take to mean "thread-safe."
Run Duration values are like batch times such that, if you set them to 2 seconds, it allows the NiFi framework to execute the processor for up to 2 seconds, then treats all of the executions during that time as a single batch which is more efficient in terms of updating internal repositories—more efficient because it takes a comparatively long time to start up and stop a processor.
But, this creates a trade-off between latency and through-put.
A Run Duration of 0 means basically no batching such that each flowfile moves through the system independently as fast as possible, therefore resulting in lower latency.
Conversely, a higher Run Duration value means an individual flowfile may not be transferred from the processor until a batch (of multiple files) is complete, which makes the flowfile take longer to reach the end of the flow, but it may lead overall to more flowfiles being processed in the same time period, thus higher through-put. This is because the start-up and shutdown latency of a processor and the time taken to update internal repositories are subjugated to batching a lot of flowfiles at the same time before yielding execution to other processors.
If both Run Schedule and Run Duration are set for a processor, the processor will start processing according to Run Schedule and then continue processing for the duration specified by Run Duration.
A processor that offers a Run Duration slider:
A processor that offers no Run Duration slider:
You are only going to benefit from setting Run Duration to (let's say) 50ms on condition that the processing of each incoming flowfile to your processor is taking fractions of the 50ms duration.
When you set Run Duration on a lot of processors and those threads are executed, they will consume that CPU thread for possibly longer then needed. This means that other processors may end up starved—waiting longer for a thread.
Let's say your processor happens to take 10ms to process a flowfile. That means that with a 50ms Run Duration setting it would put 5 flowfiles within the single thread's execution. But, what happens if the incoming connection queue only has 1 flowfile at the time the processor is scheduled to execute? The processor will still hold that thread for 40ms longer than needed. That is 40ms of that thread's CPU time not available to another processor.
Since there is some time overhead in starting and stopping processors, Run Duration is very useful when you have a high sustained dataflow. But, it can actually decrease performance when used in dataflow where there is not a high volume of flowfiles. (Note that "high volume" is relative to the processor's designed task.)
Last, this takes into account that NiFi has a configurable thread pool size. If you have 200 processors, they cannot all execute at the same time as there is only so much CPU available. Many processors will end up waiting in line for their chance at the CPU.
To set Run Duration in a JUnit test, use:
import org.apache.nifi.util.TestRunner; import org.apache.nifi.util.TestRunners; @Test public void test() { private TestRunner runner = TestRunners.newTestRunner( processor = new processor-name() ); ; runner.setRunSchedule( ( long ) milliseconds ); runner.enqueue( flowfile-content-as-a-stream ); runner.run( 1 ); }
Surprise, in the UI, of a working instance of NiFi 1.28.1, I get:
Unable to communicate with NiFi Please ensure the application is running and check the logs for any errors.
I had changed since it worked some logic inside a custom processor that is neither of those in the error.
Checking the logs, I find nothing except in nifi-app.log the following. The two processors are my own.
2025-07-21 17:14:22,787 ERROR [Timer-Driven Process Thread-2] c.i.processor.CreateAttributes CreateAttributes[id=90508e0f-0195-1000-1579-ff0c3317c9a3] Encountering difficulty starting. (Validation State is INVALID: ['Relationship Success' is invalid because Relationship 'Success' is not connected to any component and is not auto-terminated]). Will continue trying to start. 2025-07-21 17:14:22,787 ERROR [Timer-Driven Process Thread-8] c.i.processor.SplitHl7v4Resources SplitHl7v4Resources[id=ed6de974-0191-1000-fa4b-0830f49ec895] Encountering difficulty starting. (Validation State is INVALID: ['Relationship ready--resource split out' is invalid because Relationship 'ready--resource split out' is not connected to any component and is not auto-terminated, 'Relationship failed--no Bundle' is invalid because Relationship 'failed--no Bundle' is not connected to any component and is not auto-terminated]). Will continue trying to start.
I didn't understand why either of these processor instances would have lost relationship-arc connections with other components though doubtless I did something to break (but what?).
I would like to doctor flow.xml.gz to "fix" whatever is needed to get back up and running (rather than removing my flow(s) and starting from scratch. I have done similar things in the past successfully (unzipping, editing, then re-zipping), but I do not know how to "trick out" relationships. Also, I don't actually remember what components these might be connected to because the flow(s) are non trivial despite that I am able to find the instances in the unzipped flow.xml:
russ@tirion ~/dev/nifi/nifi-1.28.1/conf $ fgrep 90508e0f-0195-1000-1579-ff0c3317c9a3 flow.xml [CreateAttributes] <id>90508e0f-0195-1000-1579-ff0c3317c9a3</id> <destinationId>90508e0f-0195-1000-1579-ff0c3317c9a3</destinationId> russ@tirion ~/dev/nifi/nifi-1.28.1/conf $ fgrep ed6de974-0191-1000-fa4b-0830f49ec895 flow.xml [SplitHl7v4Resources] <id>ed6de974-0191-1000-fa4b-0830f49ec895</id> <sourceId>ed6de974-0191-1000-fa4b-0830f49ec895</sourceId> <sourceId>ed6de974-0191-1000-fa4b-0830f49ec895</sourceId> <sourceId>ed6de974-0191-1000-fa4b-0830f49ec895</sourceId> <sourceId>ed6de974-0191-1000-fa4b-0830f49ec895</sourceId> <sourceId>ed6de974-0191-1000-fa4b-0830f49ec895</sourceId> <destinationId>ed6de974-0191-1000-fa4b-0830f49ec895
It turns out, according to Nissim Shiman, that in flow.xml.gz, scheduledState can be changed from RUNNING to DISABLED for each of these processors and these messages shouldn't appear on start-up nor start-up getting aborted.
This is an unsupported operation, with potential for unknown side effects.
In my case, it appears to have worked.