XQuery, Saxon and BaseX Notes
Russell Bateman
October 2015
last update:
XQuery, Saxon and BaseX NotesRussell Bateman |
I downloaded from http://sourceforge.net/projects/saxon/files/Saxon-HE/9.6/:
SaxonHE9-6-0-7J.zip
For pom.xml:
<dependency> <groupId>net.sf.saxon</groupId> <artifactId>Saxon-HE</artifactId> <version>9.6.0-7</version> </dependency>
Note: to pretty-print any XML that's not got newlines and tabs, try these commands:
$ mv filename.xml tmp.xml
$ cat tmp.xml | xmllint --format - > filename.xml
XQuery is an extremely well-defined, mature and powerful W3C standard that has many implementations and does exactly this kind of thing. You can do some really sophisticated stuff, but for simple XML extractions, the XQuery scripts are correspondingly simple.
XQuery uses standard XPath expressions to drill into XML structure, and it supports various boolean tests and string functions to get just what you need. You can define your own functions. You can output XML (with or without a header), partial XML-like content, or even plain text. I've used XQuery happily to "down-translate" selected information from XML dictionaries directly into non-XML source files that can be compiled by the Xerox lexc program, for example. And I'd use it again to down-translate from XML dictionaries into Kleene source code, though I haven't gotten around to it yet.
One implementation of XQuery is available in the Saxon library (which has free and commercial versions, Java and .NET). XQuery is also built into every serious XML editor (I think), like oXygen. I'll redo your example using saxon.
First, I have defined a little bash alias on OS X that allows me to invoke XQuery easily from the command line:
alias xquery='java -cp /home/russ/dev/xquery/saxonHE9.6.0.7J/saxon9he.jar net.sf.saxon.Query '
As you see, it invokes the net.sf.saxon.Query function in saxon9he.jar, which is the free "home edition" of the Saxon library that you can easily download from sourceforge.net/projects/saxon/files/.
Here's a slightly simplified version of a patient database (residing in filename.xml):
<?xml version="1.0" encoding="UTF-8"?>
<ClinicalDocument>
<recordTarget>
<patientRole>
<patient>
<name use="L">
<given>Amelia</given>
<given>M</given>
<family>Earhart</family>
</name>
</patient>
<patient>
<name use="L">
<given>Mortimer</given>
<given>J</given>
<family>Snurd</family>
</name>
</patient>
<patient>
<name use="L">
<given>Boone</given>
<family>Pickens</family>
</name>
</patient>
<patient>
<name>
<given>Ronald</given>
<given>M</given>
<family>Reagan</family>
</name>
</patient>
<patient>
<name use="L">
<given>Alexander</given>
<given>John</given>
<family>Ellis</family>
</name>
</patient>
</patientRole>
</recordTarget>
</ClinicalDocument>
And here's a trivial XQuery script that opens the XML file, iterates through the <patient> elements (restricted to those with a <name> child element that has the use="L" attribute, using standard XPath notation) and prints out the full_names as elements. The script is called script.xq.
for $p in doc("filename.xml")/ClinicalDocument/recordTarget/patientRole/patient[name/@use="L"]
return <full_name>{concat(data($p/name/family), ", ", data($p/name/given[1]), " ",
data($p/name/given[2]))}</full_name>
There are, of course, many ways to express such an extraction in XQuery; this one is rather abbreviated. One simpler, but perhaps less efficient, version assumes that <patient> elements are always in the same context:
for $p in doc("filename.xml")//patient[name/@use="L"]
return <full_name>{concat(data($p/name/family), ", ", data($p/name/given[1]), " ",
data($p/name/given[2]))}</full_name>
The script can be invoked this way, using my little alias
$ xquery -q:script.xq
And the output is:
<?xml version="1.0" encoding="UTF-8"?> <full_name> Earhart, Amelia M </full_name> <full_name> Snurd, Mortimer J </full_name> <full_name> Pickens, Boone </full_name> <full_name> Ellis, Alexander John </full_name>
If you want a wrapper element to appear around the <full_name> elements, to make it at least well-formed XML, you can modify the script to something like this:
<full_names>{
for $p in doc("filename.xml")/ClinicalDocument/recordTarget/patientRole/patient[name/@use="L"]
return <full_name>{concat(data($p/name/family), ", ", data($p/name/given[1]), " ",
data($p/name/given[2]))}</full_name>
}</full_names>
And the output is:
<?xml version="1.0" encoding="UTF-8"?> <full_names> <full_name>Earhart, Amelia M</full_name> <full_name>Snurd, Mortimer J</full_name> <full_name>Pickens, Boone </full_name> <full_name>Ellis, Alexander John</full_name> </full_names>
You can also specify the XML file to process from the command line, rather than wiring it into the XQuery script, e.g. with the following script (script2.xq), which also suppressed the XML declaration and indents (pretty-prints) the output.
declare option saxon:output "omit-xml-declaration=yes" ;
declare option saxon:output "indent=yes" ;
<full_names>{
for $p in ./ClinicalDocument/recordTarget/patientRole/patient[name/@use="L"]
return <full_name>{concat(data($p/name/family), ", ", data($p/name/given[1]), " ",
data($p/name/given[2]))}</full_name>
}</full_names>
invoked using
$ xquery -s:filename.xml -q:script2.xq
which outputs
<full_names> <full_name>Earhart, Amelia M</full_name> <full_name>Snurd, Mortimer J</full_name> <full_name>Pickens, Boone </full_name> <full_name>Ellis, Alexander John</full_name> </full_names>
You can also specify an output file with -o
$ xquery -s:filename.xml -q:script2.xq -o:outfile.xml
There are many other options, but, as you can see, simple extractions need only correspondingly simple XQuery scripts.
It really started out as a database tool, an attempt to replace SQL by XML. It's apparently never escaped that purpose or mindeset. Therefore, somewhat surprisingly...
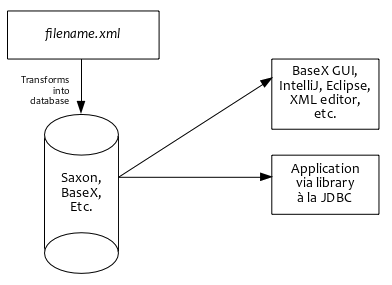
So, this begs the following questions:
This is all in comparison with SAX which is very fast (3), light (1) and free (2).
Notes taken while using BaseX, 28 October 2015...
$ sudo apt-get install basex # (you get 7.7.2 on Mint 17 as of today).
One tutorial, http://www.learndb.com/databases/basex-tutorial-for-using-an-xml-native-database-management-system, called the BaseX software a DBMS.
In http://docs.basex.org/wiki/GUI, the XML file one is analyzing seems to be called "the database." I believe this is because a) xQuery was developed to exploit databases that spoke XML and b) to keep up with the paradigm, why not treat XML content as if a database?
In the BaseX GUI, the place to type XPath expressions is in the upper left-hand window whose tab appears to be "file." This appears to be called the Editor window.
Other windows are bottom-left, Result and bottom-right, Query Info.
Here's the tutorial's lone query:
for $x in doc("factbook")//country
let $var1 :=number($x/@population)
where $var1<1000000
order by $x/@population
return $x/name