Notes on Map-reduce and Hadoop
This hasn't bubbled up to the top of my list, but I'm starting to set notes aside as I happen onto them, for example, in discussions with people who seem to know something about this topic, and I write them down, draw them up, etc.
Map/reduce is an algorithm that makes use of massively parallel operations over which a set of (or single) results is obtained.
Map takes input data and processes it to produce key-value pairs. Imagine temperature reports for dozens of cities over years. You ask map to produce a list of cities and temperatures for each.
Reduce aggregates the key-value pairs to produce final results. These results are, if you're looking for maximum temperature, a list of cities and the maximum temperature for each.
Ancient world example
Census takers were sent out by Rome to every city, one worker per city. Each counts the number of people in his city and reports it back to the Senate. (This is "map.") The Senate adds up the tally from each city into a single number of Roman citizens. (This is "reduce.")
The point is that this was more efficient than to send out one worker to visit every city and come back years later with a single tally.
Illustration
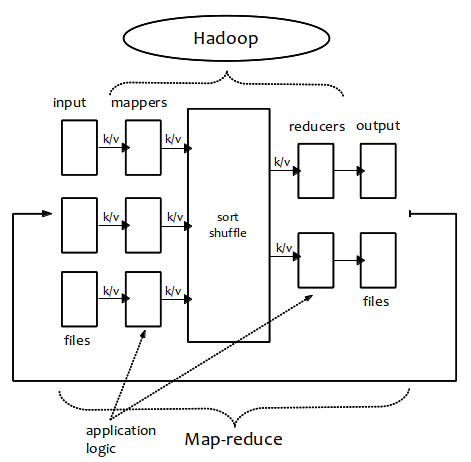
More map-reduce...
Map, filter and reduce can all operate independently. Or, they can be chained together.
Filter
A filter operates on (let's say) an array. It returns a new array that is, at most, as big as the original one (but, usually shorter) since the filter allows through only those elements that conform to some condition.
Map
Map is a transformational action. Map loops over (again, let's say) an array and returns a new element for each original one.
Reduce
Reduce, looping over (again) an array, allows for collecting the elements into some other collection, e.g.: a new array, an object, a number, etc. The result is limited only by your needs (or imagination).
Chaining
Sophisticated (and practical) use of these concepts might lead you to chain the output of a filter function first to remove elements you don't want (for whatever reason), then transform them (using a mapping function) into something else. You may chain instead with a reducing function to convert or transform the original elements (that survive filtering) into anything else you can imagine.